DataOps com uso de DBT e Snowflake
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
Não basta ter pipelines carregando dados para uma plataforma de dados analítica (Data Lakehouse) e usuários conectados construindo relatórios. Em algumas organizações isso pode ser caótico.
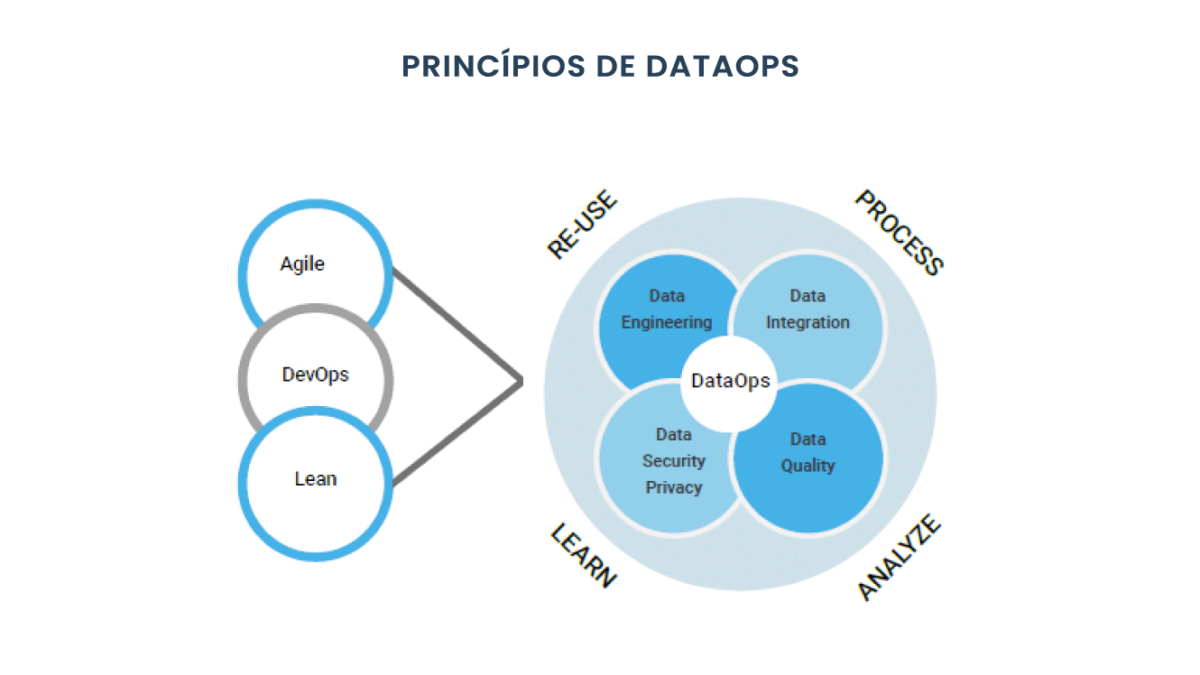
As “esteiras de dados” (nome usado para os fluxos de dados para construção de data products) devem garantir que as organizações possam coletar, armazenar, processar e utilizar dados com facilidade para criar relatórios ou produtos que sejam capazes de resolver problemas de negócios. O principal foco deve ser minimizar o tempo que os times gastam em detalhes técnicos sobre implementação, implantação e monitoramento de suas soluções e liberar as equipes de negócios para que elas possam realmente focar nas soluções que potencializem e acelerem o sucesso da empresa.
A ideia é que os times de Analytics Engineering atuem focados em data centric, apoiando outras equipes de engenharia e análises a resolverem problemas de qualidade e confiabilidade de dados, não apenas atuando em solicitações ad-hoc (resolvendo um problema de cada vez).
A seguir, focaremos nas habilidades de processamento de dados da plataforma Snowflake por meio do uso de dbt.
1. Descentralização da Modelagem de Dados
O Snowflake é utilizado como solução de data lakehouse para criar produtos de dados para análises, machine learning, API, monetização através de sharing e outros.
Dbt é uma ferramenta para transformação de dados de código aberto, baseada em SQL, desenvolvida pela dbt Labs, que simplifica a implementação de DataOps a partir de pipelines de análises. Com o dbt, pode-se construir facilmente modelos, testes e documentar ativos de dados com base em transformações de origem desenvolvidas em SQL. Os artefatos resultantes geralmente assumem a forma de um conjunto de tabelas e visualizações em um data warehouse. Pode-se desenvolver modelos e testes dbt usando a CLI de código aberto do projeto principal e integrá-los em qualquer ambiente de tempo de execução.
Uma solicitação comum de desenvolvedores é poder criar modelos sobre os dados de produção, pois as informações contidas em ambientes de homologação podem ser diferentes e os volumes serem insignificantes para testar o desempenho dos modelos. A solução para este problema é desenvolver modelos de dados diretamente em produção, sobre os dados reais! Essa configuração pode ser simplificada a partir de um clone do database no Snowflake em alguns segundos.
Em termos práticos, o desenvolvedor, em qualquer projeto dbt, criará um recurso no git que será complementado por um banco de dados de recursos/desenvolvimento no Snowflake. Esse banco de dados provavelmente será destruído assim que o branch de recursos for mesclado no branch principal do git.
2. Desenvolvimento
2.1. Modelo de projeto
Para começar, crie um modelo de projeto dbt no Github que qualquer equipe possa usar para iniciar seu próprio projeto. Este modelo contém um README de passo a passo, pacotes dedicados para extrair macros dbt comuns, bem como fontes e perfis de tabelas comuns com variáveis ambientais. A barreira de entrada para desenvolver em produção é, portanto, muito baixa, dependendo do acesso correto aos dados e dos recursos do Snowflake terem sido concedidos anteriormente.
2.2. Banco de dados de recursos
Para permitir que os desenvolvedores de dbt trabalhem fora da produção, crie primeiro funções dedicadas por projeto no formato <PROJECT>_DBT_DEVELOPER com acesso subjacente a um warehouse dedicado <PROJECT>_WH (tamanho: small, política de dimensionamento: econômico) e acesso aos dados que o projeto requer. Com essa função, os desenvolvedores podem criar bancos de dados de recursos onde todas as tabelas/views serão construídas via dbt durante o desenvolvimento.
O perfil dbt (definido no local padrão ~/.dbt/profiles.yml) de um desenvolvedor dever ser agnóstico para o projeto em que for trabalhar, conforme abaixo. Aqui o nome da variável PROJECT será previamente definido, juntamente com o DBT_DATABASE_SUFFIX, que, idealmente, terá o mesmo nome da story do branch/JIRA do recurso Git.
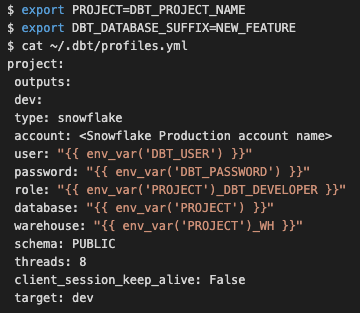
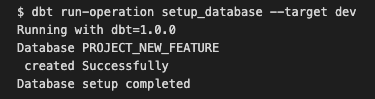
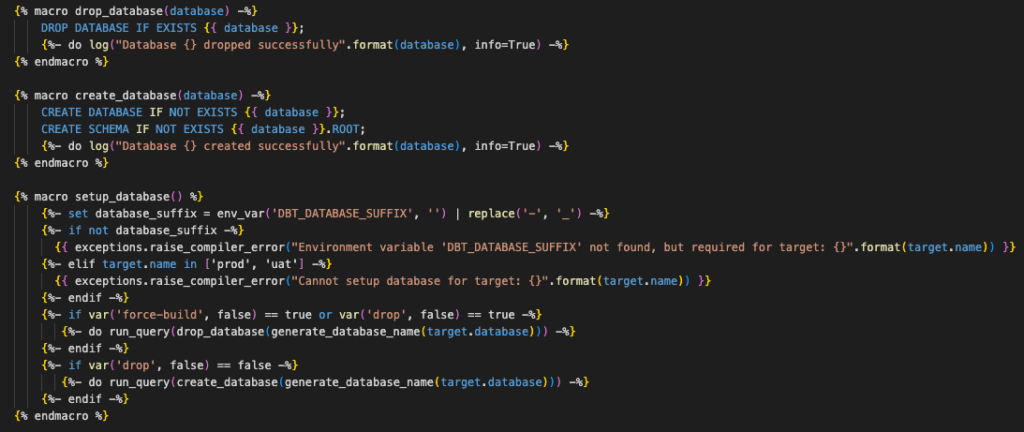
Com a configuração acima, os desenvolvedores podem criar seu banco de dados de recursos por meio da macro setup_database que foi previamente definida pela equipe de dados (anexo 1) e está contida em um repositório Github dedicado, podendo ser obtida como um pacote dbt.
Uma vez criado, o fluxo de trabalho de dados para desenvolvimento tem a seguinte aparência:
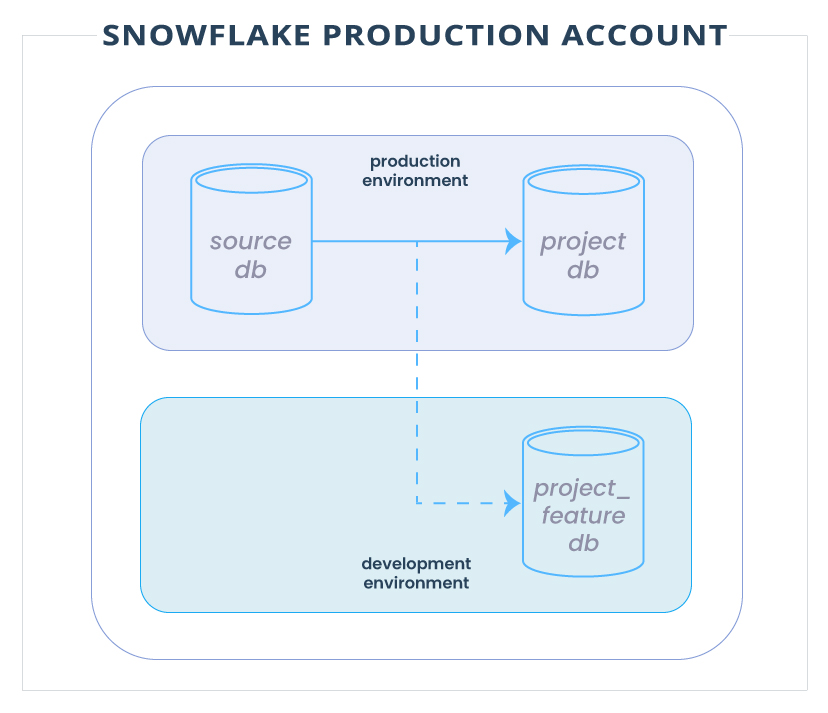
Vale a pena notar que os bancos de dados de recursos são descartados automaticamente por meio de um processo separado se nenhuma consulta tiver sido executada na base nas últimas duas semanas.
2.3. Retenção
Durante o desenvolvimento de novos modelos, os desenvolvedores de dbt podem querer testar apenas em um subconjunto dos dados de produção (evitando assim consultar tabelas com um enorme volume de registros). Para acelerar o desenvolvimento e economizar recursos, opte por usar variáveis de retenção opcionais que podem ser invocadas pelos desenvolvedores. Para fazer referência apenas a um subconjunto dos dados existentes contidos em uma tabela, os parâmetros de retenção podem ser adicionados às origens definidas em um arquivo sources.yml conforme abaixo:
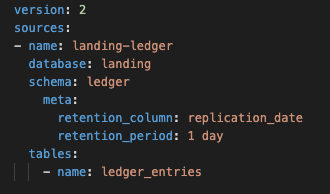
Para aplicar a filtragem de fonte de dados (anexo 2), adicione parâmetros como metadados, ou seja, a coluna de retenção e o período de retenção, que permitem filtrar os dados anteriores a um período de tempo definido. No exemplo acima, quaisquer registros que contenham uma data de replicação com mais de 1 dia serão filtrados da origem.
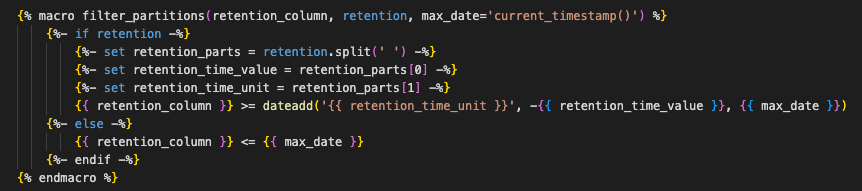
Simplificando, isso significa que estamos adicionando uma cláusula WHERE ao fazer referência à tabela de origem existente.

No exemplo acima, qualquer referência a LANDING.LEDGER.LEDGER_ENTRIES será filtrada para registros nos quais a data de replicação é mais recente que 1 dia.
Observe que os metadados acima são aplicados no nível do schema, o que significa que quaisquer tabelas que contenham a retenção da coluna definida terão a retenção aplicada. A retenção de schema pode ser substituída definindo os metadados diretamente no nível da tabela, conforme abaixo:
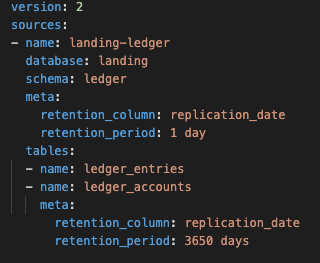
O exemplo acima significa que os dados que estão na tabela de origem LANDING.LEDGER.LEDGER_ENTRIES serão filtrados para o último dia, mas os dados na tabela LANDING.LEDGER.LEDGER_ACCOUNTS serão filtrados para os últimos 10 anos. Se não tivéssemos definido uma exceção para a tabela LANDING.LEDGER.LEDGER_ACCOUNTS, ela teria herdado as definições no nível do schema (1 dia).
2.4. Amostragem
Uma ideia inicial para acelerar o desenvolvimento e permitir o acesso a tabelas semelhantes à produção é usar amostragem. A ideia básica da amostragem é permitir que um ambiente de desenvolvimento semelhante ao de produção fosse criado de forma rápida e barata usando uma funcionalidade nativa do Snowflake para usuários sem ter que clonar bancos de dados inteiros ou tabelas em grande escala de produção ou permitir que os usuários interajam com a produção diretamente durante o desenvolvimento (anexo 3).
No entanto, existe um problema em torno das tabelas de amostragem confiáveis ao unir conjuntos de dados. Se você pensar em uma estratégia típica de data warehouse, que divide tabelas entre fatos e dimensões, como poderíamos explicar algum trabalho de desenvolvimento que precisasse de um conjunto completo de dimensões para informar as tabelas de fatos? Ou como poderíamos testar todos os casos extremos em uma tabela de fatos com apenas uma amostra e avançar de forma confiável para produção?
2.5. Fontes
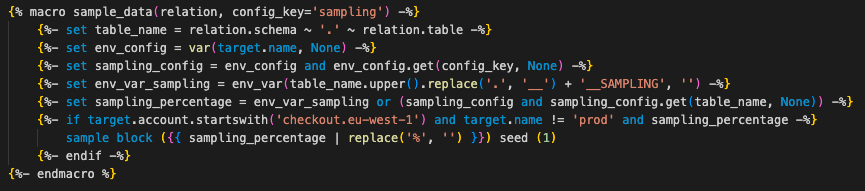
Para tornar a retenção e a amostragem transparentes para os usuários finais, crie uma macro que substitui a macro dbt de origem integrada (anexo 4).
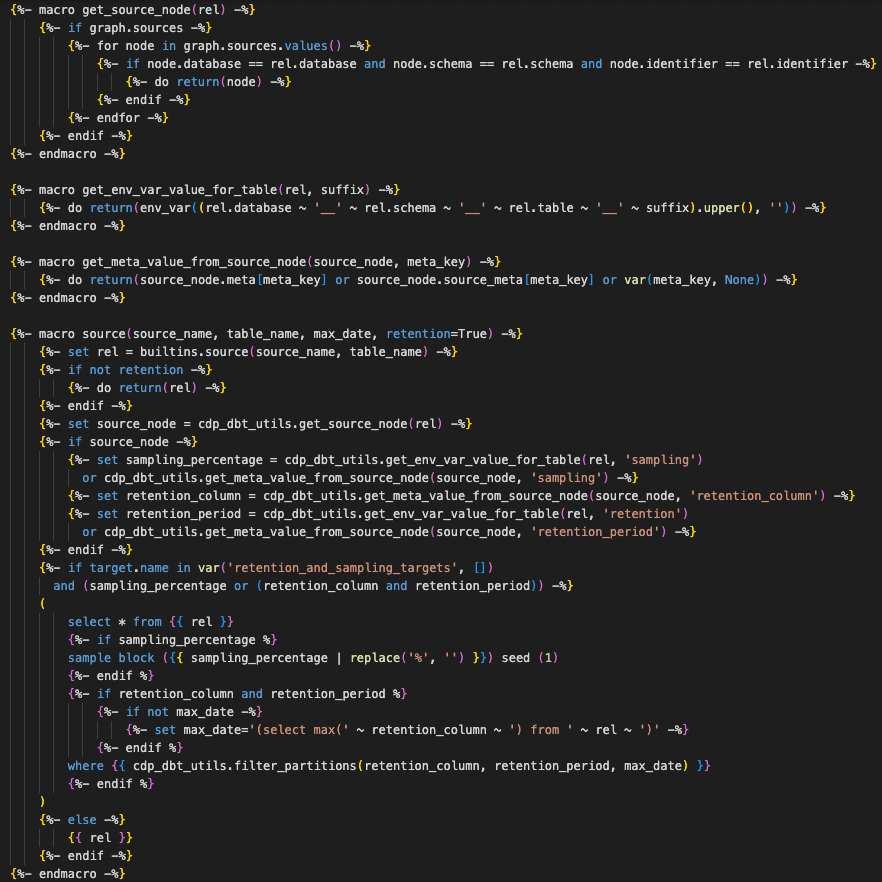
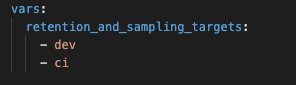
Essa macro aplica retenção e amostragem com base nos destinos definidos no arquivo dbt_project.yml. A maioria dos projetos dbt, por padrão, usa retenção para desenvolvimento e CI:
Os desenvolvedores podem, assim, chamar a macro de origem como fariam normalmente em seu código, sabendo que desenvolverão apenas com um subconjunto de dados e que a macro se comportará exatamente como a de origem integrada quando os modelos estiverem sendo executados em produção.
3. CI/CD
Depois que a modelagem e o desenvolvimento de dados estiverem concluídos, para garantir que apenas código de alta qualidade seja implantado na produção, desenvolva e modele pipelines de implantação robustos. Eles incluem todas as etapas necessárias para testar, validar e garantir que os novos modelos ou as alterações em um modelo existente sejam da mais alta qualidade.
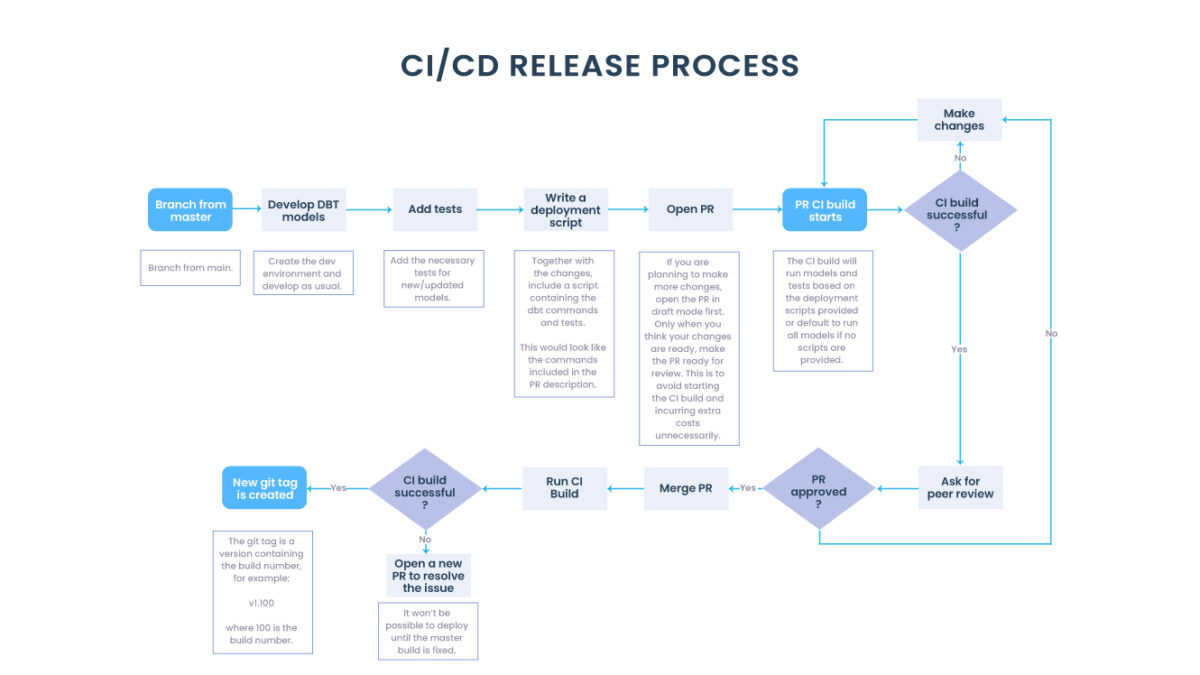
3.1. Processo de lançamento
Quando uma solicitação pull na ramificação principal é aberta, ela aciona uma etapa de CI no pipeline para verificar e validar se os modelos dbt ainda são executados conforme o esperado. Os desenvolvedores conseguem ver instantaneamente no Github se a compilação do CI foi aprovada ou falhou. Nesta etapa, o desenvolvedor tem duas opções — executar a compilação de CI em todo o banco de dados ou adicionar scripts de implantação para seu recurso específico.
Para reduzir custos e tempo, geralmente os desenvolvedores adicionam scripts para todas as implantações de recursos. Os pipelines usam esses scripts para automação.
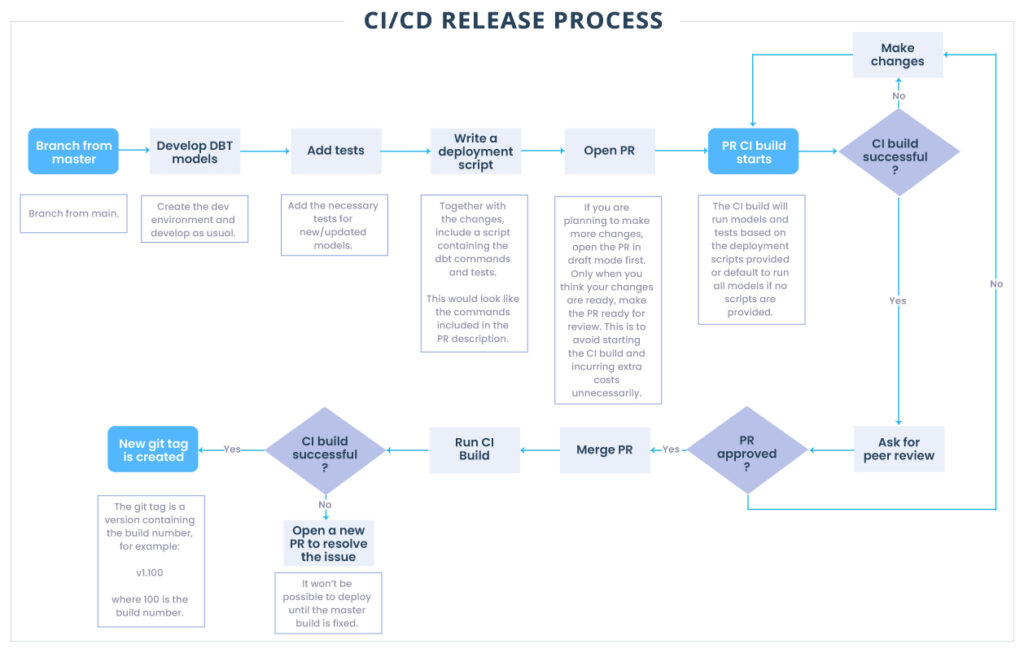
Dependendo do resultado da construção do CI, o recurso precisará de algumas alterações ou estará pronto para uma revisão por pares. Depois que as alterações são criadas e aprovadas com sucesso por uma revisão por pares, a ramificação do recurso é mesclada ao principal e aciona as etapas restantes no pipeline.
Um pipeline de implantação médio contém todos os estágios a seguir, mas pode ser limitado apenas a Build e Deploy to Prod para projetos mais simples.

Depois que uma solicitação de pull for mesclada na ramificação principal, a etapa de compilação será executada para a ramificação principal e, se for bem-sucedida, uma nova tag de versão será criada no Github. Neste ponto, uma nova versão já está disponível para lançamento, mas ainda não foi implantada. A partir daí, ele pode ser implantado em todos os ambientes sucessivamente (UAT -> SBOX -> PROD) (ou, como mencionado anteriormente, diretamente na Produção para projetos mais simples).
3.2. Modelagem
Nosso papel é apoiar as equipes de dados dos nossos clientes na modelagem e implementação de projetos dbt, reduzindo drasticamente o tempo necessário na engenharia de dados e integrações.
Para garantir que todas as equipes, sejam elas de dados ou de negócios, tenham uma excelente experiência durante todo o processo de integração é importante que os modelos de pipeline sejam muito bem definidos e organizados.
Uma boa forma de estruturar as integrações é atribuir funções específicas na plataforma de dados (Snowflake, por exemplo) para equipes e/ou projetos. Isso garante que cada função possa ter recursos dedicados (governança) para a manipulação de dados, permitindo o acompanhamento de desempenho e custos associados a essas equipes ou projetos. Assim, ganhamos maior transparência e agilidade para identificar e ajustar possíveis desvios, caso sejam observados picos de custos ou problemas de desempenho.
4. Orquestração e monitoramento
Agora que tudo está funcionando, como orquestrar e ficar de olho em um número cada vez maior de fluxos de trabalho? Como manter a confiança no estado do sistema de produção? Como escrever testes para cenários impensados? E os problemas que não estão estritamente relacionados aos dados na tabela, mas podem representar um risco para a qualidade dos dados em seus pipelines?
A triggo.ai é pioneira e especialista em MDS – Modern Data Stack & DataOps, desenvolvemos produtos e soluções que permitem nossos clientes atingir o melhor ROI para Data Analytics & AI. Fale com um de nossos especialistas!