O que é um Engenheiro de Confiabilidade de Dados?
À medida que o mundo dos negócios começa a confiar mais no aprendizado de máquina (ML), a precisão dos dados subjacentes nos quais os modelos de ML são treinados tornou-se muito mais importante.
Mas, antes de abordarmos o DRE, vamos entender de onde ele partiu…
O conceito de SRE (Site Reliability Engineering) – Engenharia de Confiabilidade de Sites, foi criado pela equipe de engenharia do Google por volta de 2004 e é atribuído a Ben Treynor Sloss.
“SRE é o que você obtém quando trata as operações como se fossem um problema de software. Nossa missão é proteger, fornecer e desenvolver o software e os sistemas por trás de todos os serviços públicos do Google, Pesquisa do Google, Anúncios, Gmail, Android, YouTube e App Engine, para citar apenas alguns, sempre atentos em sua disponibilidade, latência, desempenho e capacidade.” Google
A abordagem de SRE ajuda as equipes a encontrarem um equilíbrio entre lançar novas funcionalidades e assegurar que elas sejam confiáveis para os usuários.
Padronização e automação são dois componentes importantes do modelo de SRE. Os engenheiros de confiabilidade de sites devem sempre procurar uma maneira de aprimorar e automatizar as tarefas operacionais. Desse modo, a SRE ajuda a aumentar a confiabilidade de um sistema não somente no presente, mas também a aprimorá-la ao longo do tempo, conforme esse sistema cresce.
Por que preciso de um engenheiro de confiabilidade de dados (DRE)?
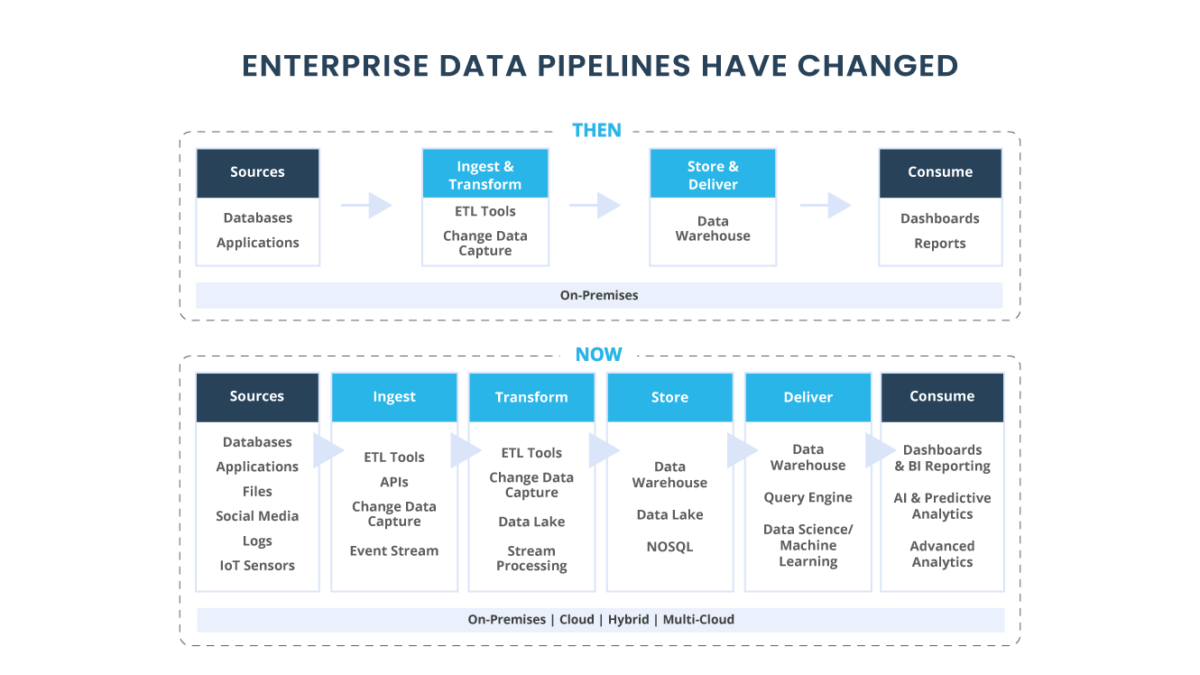
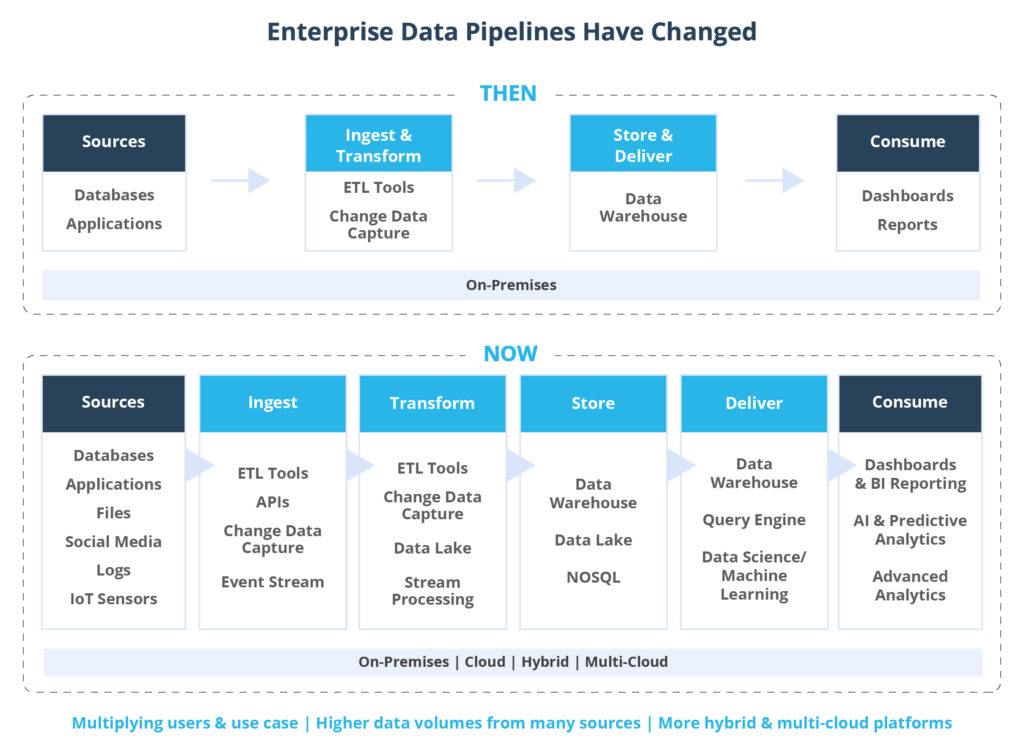
Nos últimos anos, com o surgimento de Data Warehouses em nuvem e Lakes como Snowflake, Redshift e Databricks, os pipelines de dados tornaram-se cada vez mais distribuídos e complexos, com as empresas ingerindo mais dados operacionais e de terceiros do que nunca. À medida que mais partes interessadas interagem com os dados ao longo de seu ciclo de vida, garantir a alta qualidade desses dados passou a ocupar o primeiro lugar na lista de necessidades básicas de uma equipe de dados.
Ainda assim, a confiabilidade dos dados é mais fácil de falhar do que de alcançar. Afinal, os dados podem falhar por milhões de motivos, desde problemas operacionais até alterações de código imprevistas.
Engenheiros e cientistas de dados gastam pelo menos 30% do tempo lidando com problemas de qualidade de dados. (muito conservador esses 30%, certo!)
Essa maior necessidade de confiança levou ao surgimento de uma subcategoria de engenharia de dados entre as equipes de dados chamada engenharia de confiabilidade de dados.
O engenheiro de confiabilidade de dados é responsável por ajudar uma organização a fornecer alta disponibilidade e qualidade em todo o ciclo de vida dos dados, desde a ingestão até os produtos finais, painéis, modelos de aprendizado de máquina e datasets de produção.
Como resultado, os engenheiros de confiabilidade de dados geralmente aplicam as melhores práticas de DataOps e SRE, como monitoramento contínuo, definição de SLAs, gerenciamento de incidentes e observabilidade para os dados.
O que faz um engenheiro de confiabilidade de dados?
Quando ocorrerem pipelines de dados quebrados (porque eles ocorrerão em um ponto ou outro), os engenheiros de confiabilidade de dados devem ser os primeiros a descobrir problemas de qualidade, embora nem sempre seja esse o caso. Com muita frequência, os dados ruins são descobertos primeiro em painéis e relatórios, em vez de no pipeline, ou mesmo antes.
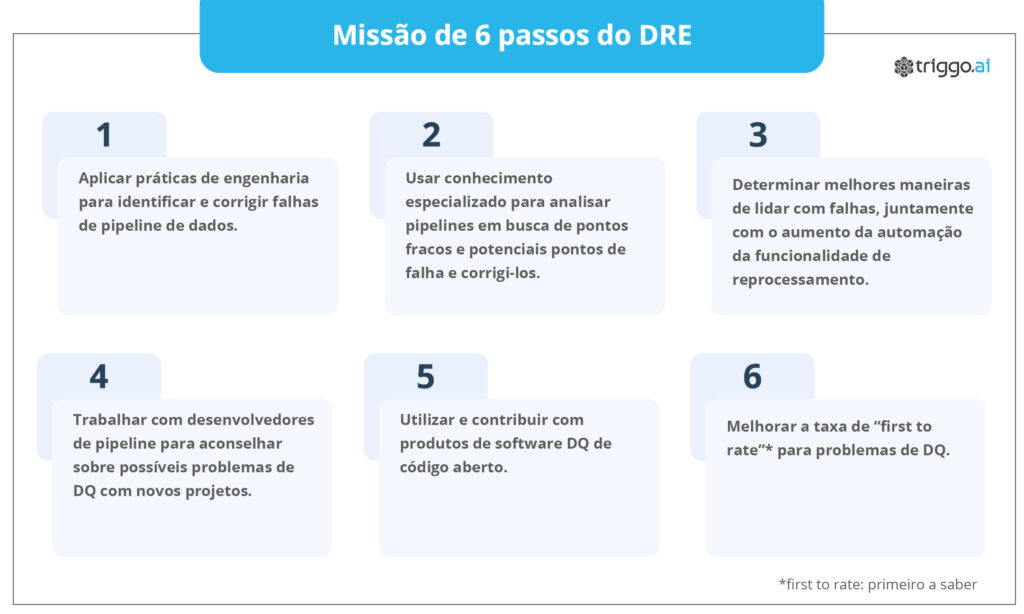
Como os dados raramente estão em seu estado ideal e perfeitamente confiável, o engenheiro de confiabilidade de dados é mais frequentemente encarregado de colocar as ferramentas (como plataformas de observabilidade de dados e testes) e processos (como CI/CD) para garantir que, quando ocorrerem problemas, eles são rapidamente resolvidos e o impacto será transmitido para aqueles que precisam saber.
Assim como os engenheiros de confiabilidade do site (SRE) são uma extensão natural da equipe de engenharia de software, os engenheiros de confiabilidade de dados (DRE) são uma extensão da equipe de dados e análise.
Muitos engenheiros de confiabilidade de dados têm uma sólida experiência em engenharia de dados, ciência de dados ou até mesmo análise de dados. A função requer uma forte compreensão de sistemas de dados complexos, linguagens de programação de computador e estruturas como dbt, Airflow, Java, Python e SQL.
Os engenheiros de confiabilidade de dados também devem ter experiência em trabalhar com sistemas de nuvem populares, como AWS, GCP, Snowflake ou Databricks, e entender as práticas recomendadas do setor para dimensionar plataformas de dados.
Conclusões
Claramente, a demanda por insights e confiabilidade nunca foi tão alta. Cada vez mais, engenheiros e analistas de dados serão encarregados de garantir a confiabilidade e a qualidade de seus sistemas de dados (seja para anaytics ou ML). E, à medida que as soluções se tornam mais complexas e as necessidades de dados aumentam, as empresas começarão a adotar novas tecnologias, processos e culturas testadas na batalha para acompanhar o ritmo acelerado de evolução.
A triggo.ai está conectada com todo o ecossistema de Data & Analytics, acompanhando de perto todas as tendências do mercado. Fale com nossos especialistas!