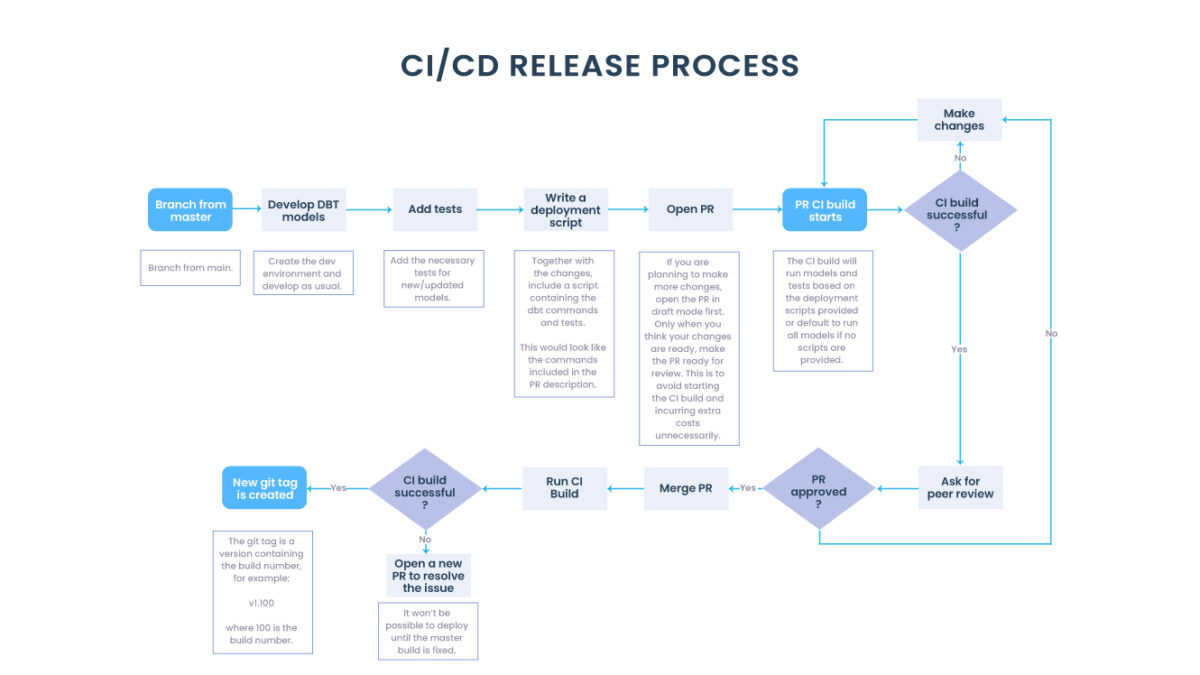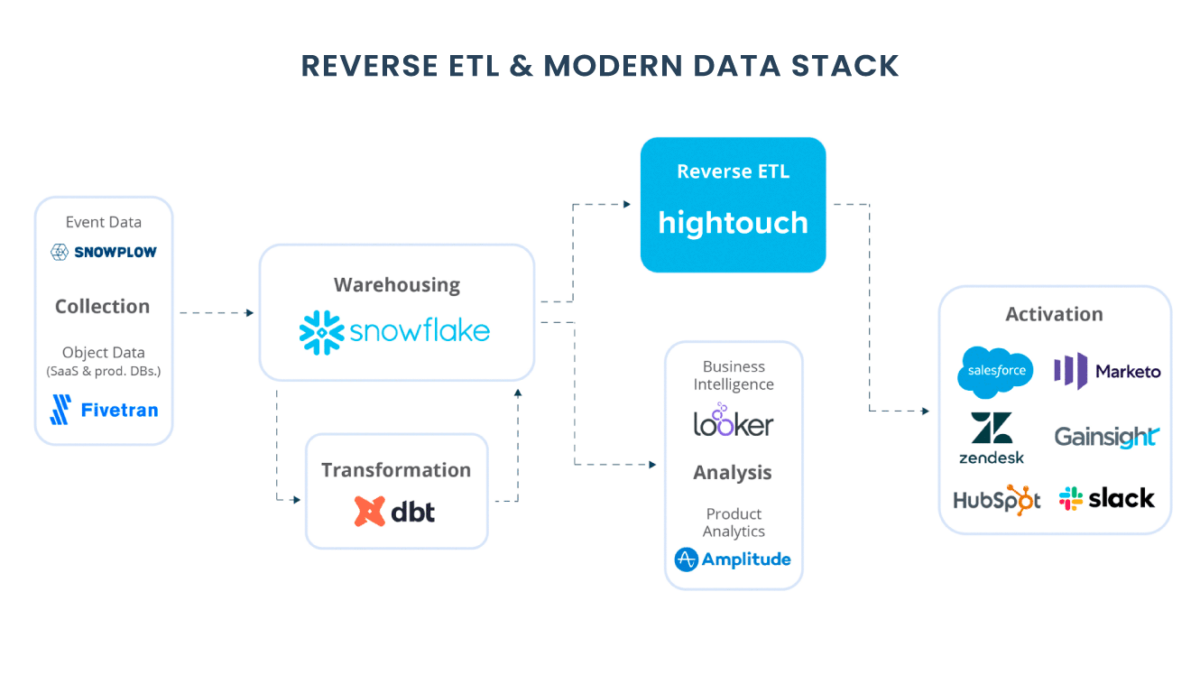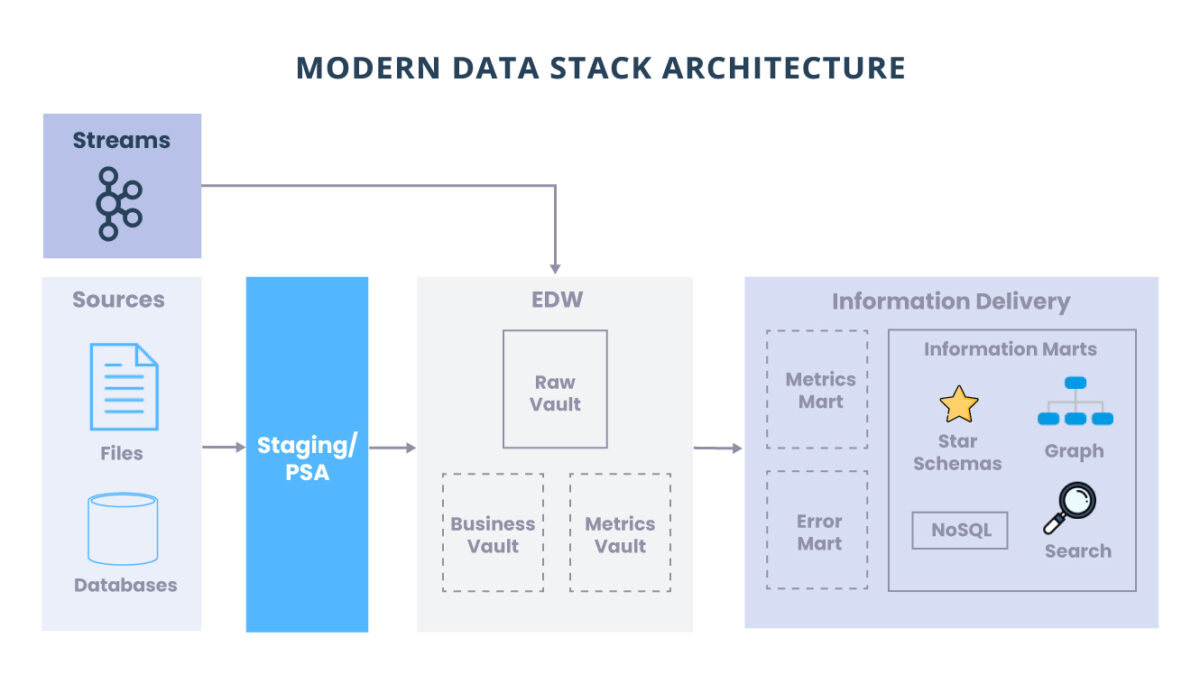
Entenda o que é Data Vault
Ao construir uma nova arquitetura de dados, um dos fatores mais importantes é estabelecer a governança da modelagem que será usada como base para a plataforma de dados.
Embora existam várias metodologias tradicionais a serem consideradas ao estabelecer um novo data lake (da Inmon e Kimball, por exemplo), uma alternativa apresenta uma oportunidade única: um Data Vault.
A utilização de uma arquitetura Data Vault permite que as empresas criem uma plataforma de dados escalável que oferece durabilidade e acelera o valor comercial.
O que é um Data Vault?
Depois de tentar e não conseguir implementar um data warehouse de grande escala com as arquiteturas existentes, Dan Linstedt e sua equipe da Lockheed Martin criaram o Data Vault, no início dos anos 90, para solucionar os desafios que enfrentavam.
Em sua essência, o Data Vault é um sistema completo que fornece uma metodologia, arquitetura e modelo para implementar com sucesso e eficiência um data warehouse altamente focado nos negócios. Há muitas maneiras pelas quais esses vários componentes podem ser utilizados e implementados, no entanto, é importante adotar as recomendações estabelecidas ao criar um Data Vault. Os projetos podem rapidamente se tornar mal-sucedidos se esses padrões não forem seguidos.
Prós e contras de usar um Data Vault
Vamos dar uma olhada em alguns dos motivos pelos quais gostaríamos de projetar um data lake usando o Data Vault e algumas das possíveis desvantagens a serem consideradas.
As vantagens são:
- Inserir apenas arquitetura;
- Acompanhamento de registros históricos;
- Mantém todos os dados (os bons e os ruins);
- Fornece auditabilidade;
- Pode ser construído incrementalmente;
- Adaptável a mudanças sem reengenharia;
- O modelo permite cargas de dados com alto grau de paralelismo;
- Tecnologia agnóstica;
- Pipelines de ingestão tolerantes a falhas.
As desvantagens são:
- Os modelos podem ser mais complexos;
- As equipes precisam de treinamento adicional para saber como implementar corretamente um Data Vault;
- Quantidade de armazenamento necessária para manter o histórico completo;
- Os dados não estão imediatamente prontos para o usuário quando são ingeridos no Data Vault (o business vault e os marts de informações precisam ser criados para fornecer valor aos negócios).
3 principais conceitos da Modelagem Data Vault
Existem três estruturas principais que compõem uma arquitetura do Data Vault:
- Hub
- Link
- Satellite
Embora as aplicações de hash descritas abaixo não sejam tecnicamente obrigatórias, o Data Vault 2.0 os recomenda. O hash oferece muitas vantagens em relação ao uso de chaves compostas ou substitutas padrão e comparações de dados:
- Desempenho da consulta: menos comparações a serem feitas ao unir tabelas.
- Desempenho de carga: as tabelas podem ser carregadas em paralelo porque os pipelines de ingestão não precisam esperar que outras chaves substitutas sejam criadas no banco de dados. Cada pipeline pode calcular todas as chaves necessárias.
- Determinístico: significa que a chave pode ser calculada a partir dos dados. Não há pesquisas necessárias. Isso é vantajoso porque qualquer sistema que tenha os mesmos dados pode calcular a mesma chave.
- Os hashes de negócios: podem ser usados para distribuir melhor os dados em muitos sistemas distribuídos de grande porte.
- Os hashes de conteúdo: podem ser usados com eficiência para detectar registros alterados em um conjunto de dados, independentemente de quantas colunas ele contenha.
- Compartilhamento de dados: as chaves com hash podem permitir altos graus de compartilhamento de dados confidenciais. Os relacionamentos entre conjuntos de dados podem ser expostos por meio de tabelas de links sem expor nenhum dado confidencial.
Nota: todas as estruturas listadas abaixo não são voláteis. Isso significa que você não pode modificar os dados nas linhas. Se for necessário atualizar uma linha, uma nova linha deve ser inserida na tabela que conterá a alteração.
Hub
Um Hub representa uma entidade de negócios principal dentro de uma empresa. Isso pode ser um cliente, produto ou uma loja.
Os hubs não contêm dados de contexto ou detalhes sobre a entidade. Eles contêm apenas a chave comercial definida e alguns campos obrigatórios do Data Vault. Um atributo crítico de um Hub é que eles contêm apenas uma linha por chave.
Link
Um Link define a relação entre as chaves de negócios de dois ou mais Hubs.
Assim como o Hub, uma estrutura Link não contém informações contextuais sobre as entidades. Também deve haver apenas uma linha representando o relacionamento entre duas entidades. Para representar um relacionamento que não existe mais, precisaríamos criar uma tabela satellite dessa tabela Link que conteria um sinalizador is_deleted; isso é conhecido como um satellite de efetividade.
Uma grande vantagem que o Data Vault tem em relação a outras arquiteturas de data warehousing é que os relacionamentos podem ser adicionados entre os Hubs com facilidade. O Data Vault se concentra em ser ágil e implementar o que é necessário para atingir as metas de negócios atuais. Se os relacionamentos não forem conhecidos no momento ou as fontes de dados ainda não estiverem acessíveis, tudo bem porque os links são criados facilmente quando são necessários. A adição de um novo Link não afeta de forma alguma os Hubs ou Satellites existentes.
Muitas vezes, com abordagens mais tradicionais, esses tipos de alterações podem levar a impactos maiores no modelo existente e nas recargas de dados. Esse é um dos fatores que torna a modelagem do Data Vault um processo ágil e iterativo. Os modelos não precisam ser desenvolvidos em uma abordagem “big bang”.
Satellite
Na arquitetura Data Vault, um Satellite abriga todos os detalhes contextuais relativos a uma entidade
No meu negócio, os dados mudam com muita frequência. Como as tabelas contextuais não voláteis podem funcionar para mim?
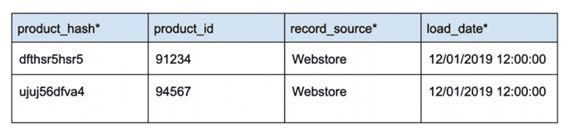
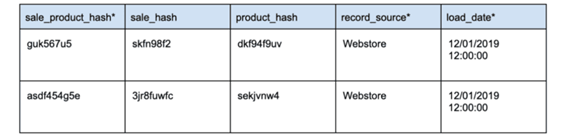
Quando houver alteração nos dados, uma nova linha deve ser inserida com os dados alterados. Esses registros são diferenciados um do outro usando a chave de hash e um dos campos obrigatórios do Data Vault: o load_date. Para um determinado registro, o load_date nos permite identificar qual é o registro mais recente.
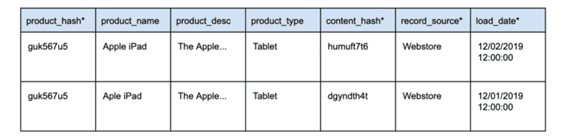
No exemplo acima, vemos dois registros para o mesmo product_hash. O registro mais recente, definido pelo load_date, corrige um erro de ortografia no campo product_name.
Mas isso não levará uma eternidade para determinar o que mudou entre a origem e o Data Vault?
Não – isso é muito eficiente com o uso de um content_hash. Embora seja opcional com um modelo do Data Vault, ele oferece uma enorme vantagem ao examinar registros que foram alterados entre os sistemas de origem e de destino.
O content_hash é calculado ao preencher a área Data Vault Staging (veja mais sobre isso abaixo) e utiliza todos os campos de dados contextuais relevantes. Quando qualquer um desses campos de dados contextuais for atualizado, um content_hash diferente será calculado. Isso nos permite detectar mudanças muito rapidamente. Dependendo da tecnologia em uso, isso seria mais comumente realizado com uma Outer Join, embora alguns sistemas ofereçam técnicas ainda mais otimizadas.
Para ajudar na diferenciação, os Satellites são criados com base na fonte de dados e sua taxa de mudança. Geralmente, você projetaria uma nova tabela Satellite para cada fonte de dados e, em seguida, separaria ainda mais os dados dessas fontes que podem ter uma alta frequência de alteração. Separar atributos de dados de alta e baixa frequência pode ajudar no rendimento de ingestão e reduzir significativamente o espaço que os dados históricos consomem. Separar os atributos por frequência não é obrigatório, mas pode oferecer algumas vantagens.
Outra consideração comum ao criar Satellites é a classificação de dados. Os satellites permitem que os dados sejam divididos com base na classificação ou na sensibilidade. Isso facilita o tratamento de considerações especiais de segurança, separando fisicamente os elementos de dados.
Data Vault vs Dimensional?
Se você trabalhou com um modelo de dados mais tradicional, a modelagem de dimensão e os esquemas em estrela serão muito familiares para você.
Em um exemplo simplificado de esquema em estrela (um pedido de venda para um estabelecimento de varejo), você pode acabar com algo assim:
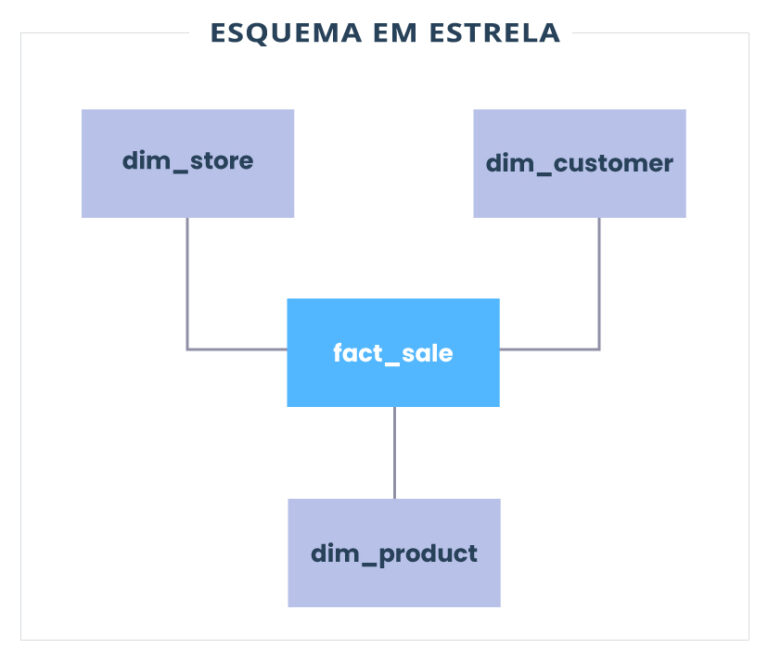
Tomando nossos conceitos de Data Vault acima e aplicando-os ao nosso mesmo exemplo, podemos acabar com algo assim:
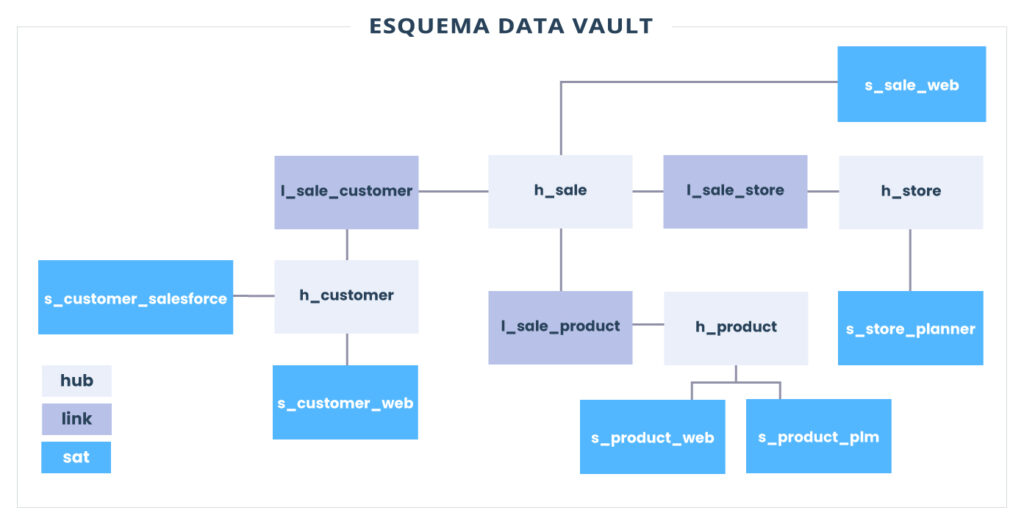
Podemos ver imediatamente que ganhamos algumas tabelas sobre nosso exemplo de esquema em estrela. Não temos mais uma única tabela Dimension representando Customer, mas a substituímos por uma tabela Customer Hub e duas tabelas Satellite. Um Satellite contém dados da instância do Salesforce de um varejista, enquanto o outro contém dados da loja virtual do varejista.
Resumindo, a metodologia do Data Vault permite que as equipes ingiram novas fontes de dados muito rapidamente.
Em vez de reengenharia do modelo e desperdiçar ciclos valiosos determinando o impacto dessas mudanças, os dados de uma nova fonte podem ser ingeridos em uma tabela Satellite completamente nova. Essa velocidade também permite que os engenheiros de dados interajam rapidamente com os usuários de negócios na criação de novos mercados de informações.
Precisa integrar entidades de negócios completamente novas ao Data Vault? Você pode adicionar novos Hubs a qualquer momento e pode definir novos relacionamentos criando novas tabelas de Link entre Hubs. Este processo tem impacto zero no modelo existente.
Modern Data Stack Architecture
O Data Vault não apenas nos ajuda a entender como devemos modelar nossos dados com eficiência, mas também nos fornece uma arquitetura multicamada que é escalável e flexível.
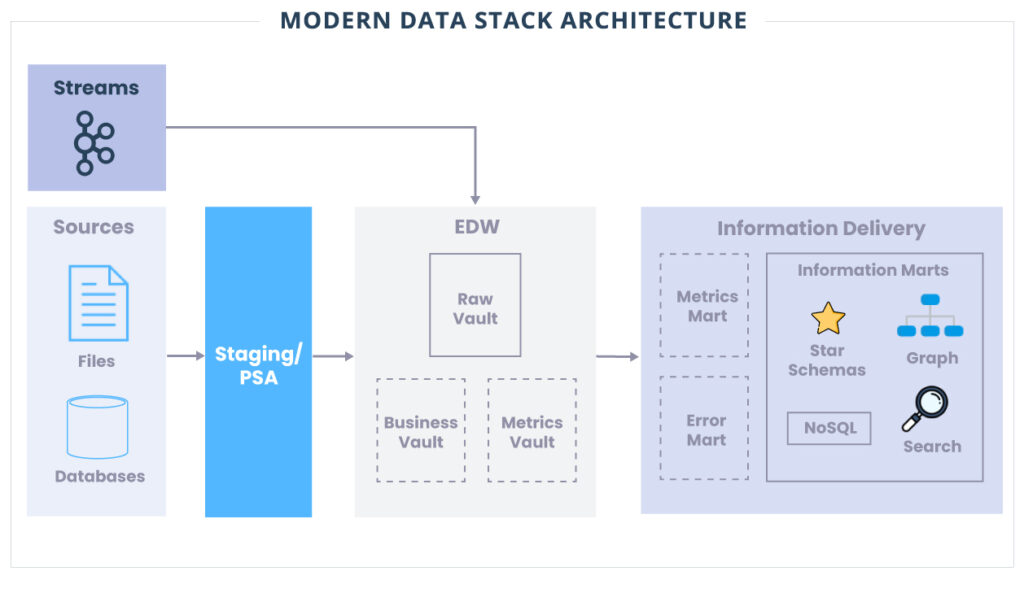
Staging
A preparação é essencialmente uma zona de destino para a maioria dos dados que entrarão no Data Vault.
Geralmente, não contém dados históricos e os dados espelham o esquema dos sistemas de origem. Vamos ingerir dados do sistema de origem o mais rápido possível, de modo que apenas regras de negócios rígidas sejam aplicadas aos dados (ou seja, qualquer coisa que não altere o conteúdo dos dados).
A área de Staging também pode ser implementada no que é conhecido como Persistent Staging Area (PSA). Aqui, os dados históricos podem ser mantidos por algum tempo no caso de serem necessários para resolver problemas ou referenciados. Um PSA também é uma ótima opção para usar como base para um Data Lake! Se você não deseja que todos os casos de uso atinjam seu data warehouse corporativo (EDW), portanto, ter um PSA/Data Lake é um ótimo recurso para habilitar Data Science, Data Mining e outros casos de uso de Machine Learning.
Idealmente, os pipelines que ingerem dados no Staging devem ser gerados o mais automatizados possível. Não deveríamos perder muito tempo ingerindo dados no Data Vault. A maior parte do nosso tempo deve ser gasto trabalhando com o negócio e implementando seus requisitos nos Information Marts.
Data Warehouses corporativos
Raw Data
Raw Data é onde mora nosso principal modelo de Data Vault (Hubs, Links, Satellites).
Os dados são ingeridos na camada Raw diretamente da camada Staging ou potencialmente diretamente na camada Raw ao manipular fontes de dados em tempo real. Ao ingerir na camada Raw, também não deve haver regras de negócios aplicadas aos dados.
A ingestão de dados no Raw é uma etapa crucial na arquitetura do Data Vault e deve ser feita corretamente para manter a consistência. Conforme mencionado anteriormente para o Staging, esses pipelines de ingestão bruta devem ser gerados o mais automatizados possível. Não devemos escrever instruções SQL manualmente para fazer a fonte para diffs de destino. Uma instrução SQL incorreta e você terá tabelas não confiáveis e inconsistentes. A genialidade do Data Vault é que ele permite padrões altamente repetíveis e consistentes que podem ser automatizados e tornam nossas vidas muito mais fáceis e eficientes.
Business Vault
O Business Vault é uma camada opcional no Data Vault onde a empresa pode definir entidades comerciais, cálculos e lógica comuns. Pode ser como Master Data ou criando lógica de negócios para ser usada em toda a empresa em vários Information Marts. Porém, isso não deve ser implementado em cada Information Mart de forma diferente, deve ser implementado uma vez no Business Vault e usado várias vezes através dos Information Marts.
Metrics Vault
O Metrics Vault é uma camada opcional usada para armazenar dados de métricas operacionais para os processos de ingestão do Data Vault. Essas informações podem ser inestimáveis ao diagnosticar possíveis problemas com a ingestão. Ele também pode atuar como uma trilha de auditoria para todos os processos que estão interagindo com o Data Vault.
Information Delivery
Informational Marts
Os Informational Marts são onde os usuários de negócios finalmente terão acesso aos dados. Todas as regras e lógica de negócios agora são aplicadas a esses Marts.
Para implementar regras e lógica de negócios, a Metodologia do Data Vault também se baseia fortemente no uso de SQL Views sobre a criação de pipelines. As visualizações permitem que os desenvolvedores implementem e interajam muito rapidamente com os negócios nos requisitos ao implementar os Information Marts. Ter muitos pipelines pode ser também apenas mais uma coisa para manter e se preocupar com a reexecução. Os usuários corporativos podem consultar Views sabendo que estão sempre acessando os dados mais recentes.
Então, isso significa que eu tenho que encaixar toda a minha lógica de negócios em Views agora?
Não – A preferência da metodologia do Data Vault se inclina para o uso de Views, mas há certas coisas para as quais as Views não são adequadas (ou seja, lógica extremamente complexa, aprendizado de máquina etc.). Se parece uma luta tentar fazer com que o SQL execute sua lógica de negócios, uma View provavelmente não é a ferramenta certa. Para esses casos, um pipeline tradicional será sua melhor aposta.
Se toda a minha lógica de negócios estiver em Views, isso não vai desacelerar meus relatórios de BI?
Como qualquer outra coisa, depende. Há muitas considerações desde o tamanho e volume dos dados, a complexidade da lógica de negócios, até a tecnologia de banco de dados e os recursos desse sistema.
Na maioria das vezes, o Views terá um bom desempenho e atenderá às necessidades da maior parte dos negócios. Se, no entanto, as exibições não estiverem funcionando para o seu caso de uso, a metodologia do Data Vault oferece estruturas mais avançadas, conhecidas como tabelas Point In Time (PIT) e Bridge, que podem melhorar muito o desempenho da junção. Como último recurso, a metodologia do Data Vault afirma que podemos materializar nossos dados (ou seja, visualização materializada ou nova tabela).
O conceito de um Information Mart também é um limite lógico. Seu Data Vault também pode ser usado para preencher outros recursos da plataforma, como NoSQL, gráfico e pesquisa. Ainda podem ser considerados como uma forma de mercado de informações. Essas ferramentas externas normalmente seriam preenchidas usando pipelines ETL.
Error Marts
Error Marts são uma camada opcional no Data Vault que pode ser útil para trazer à tona problemas de dados para os usuários de negócios. Lembre-se de que todos os dados, corretos ou não, devem permanecer como dados históricos no Data Vault para auditoria e rastreabilidade.
Metics Mart
O Metics Mart é uma camada opcional usada para apresentar métricas operacionais para fins analíticos ou de relatórios.
Avançando com sua plataforma de dados
Escolher a arquitetura de armazenamento certa para sua empresa não se trata apenas de facilidade de migração ou implementação.
A base que você construir irá apoiar ou inibir os usuários de negócios e impulsionar ou limitar o valor do negócio. A utilização do Data Vault pode não ser tradicional, mas pode ser exatamente o que você precisa para a sua organização.
A triggo.ai é pioneira na abordagem Modern Data Stack e XOps (DataOps, ModelOps e MLOps), estamos ajudando clientes a focar mais tempo na entrega de Analytics e AI, reduzindo seus esforços operacionais de dados, consequentemente maior entrega de valor. Fale com um de nossos especialistas!