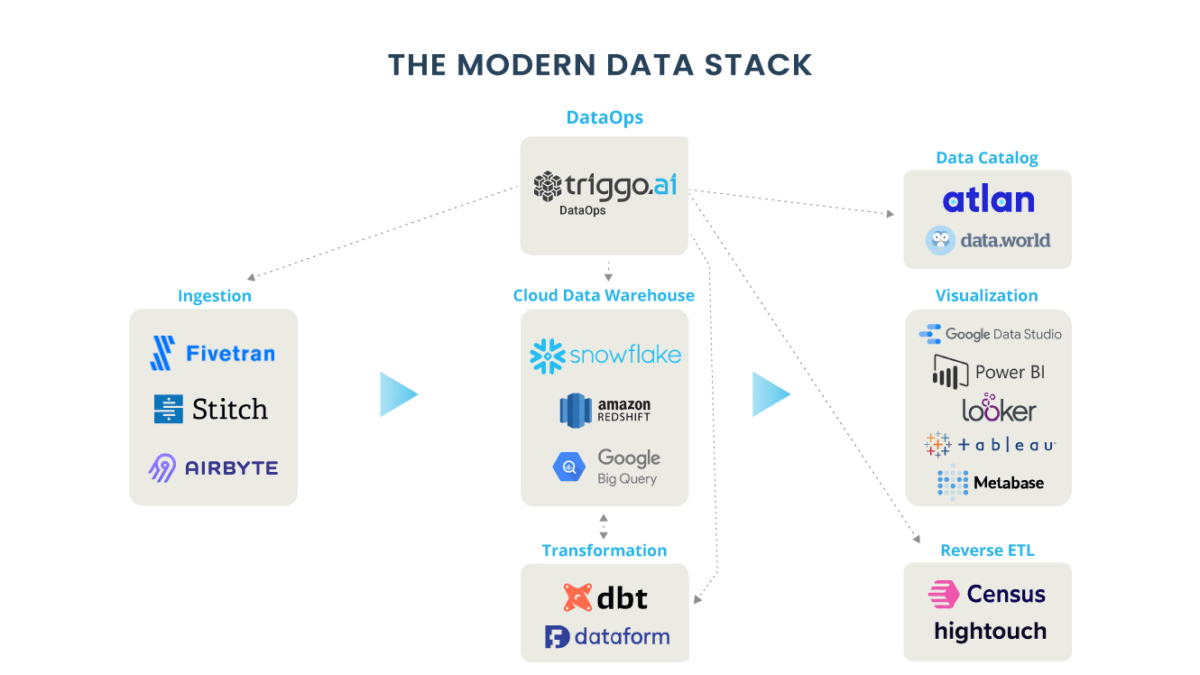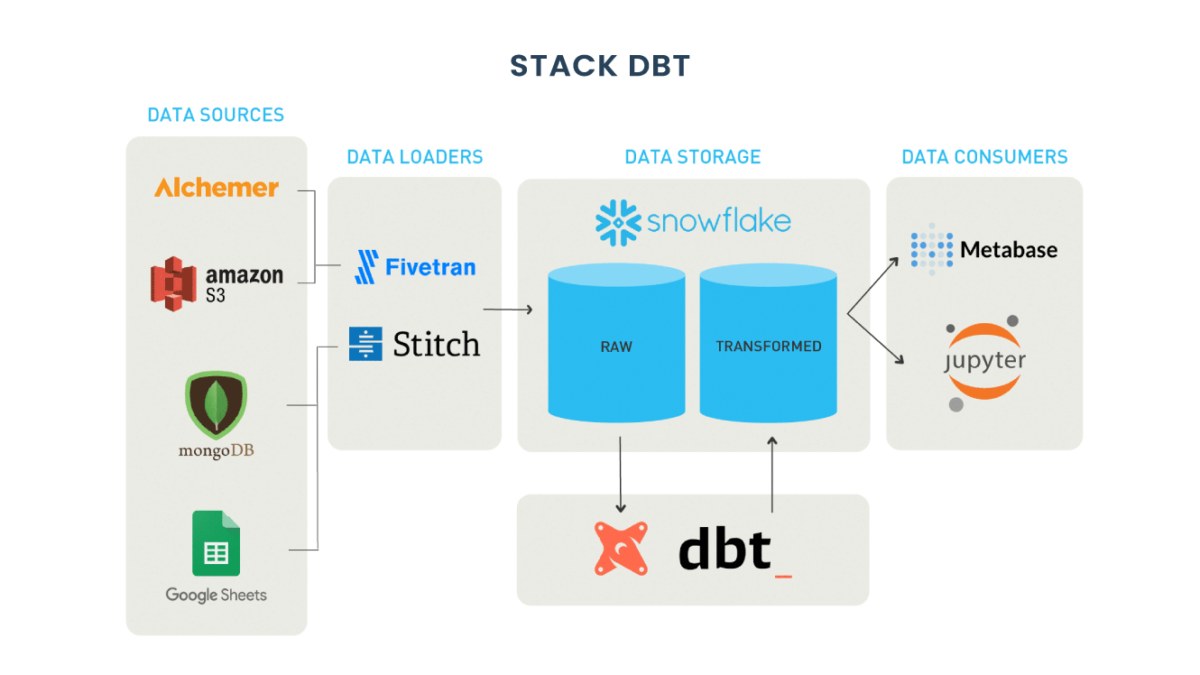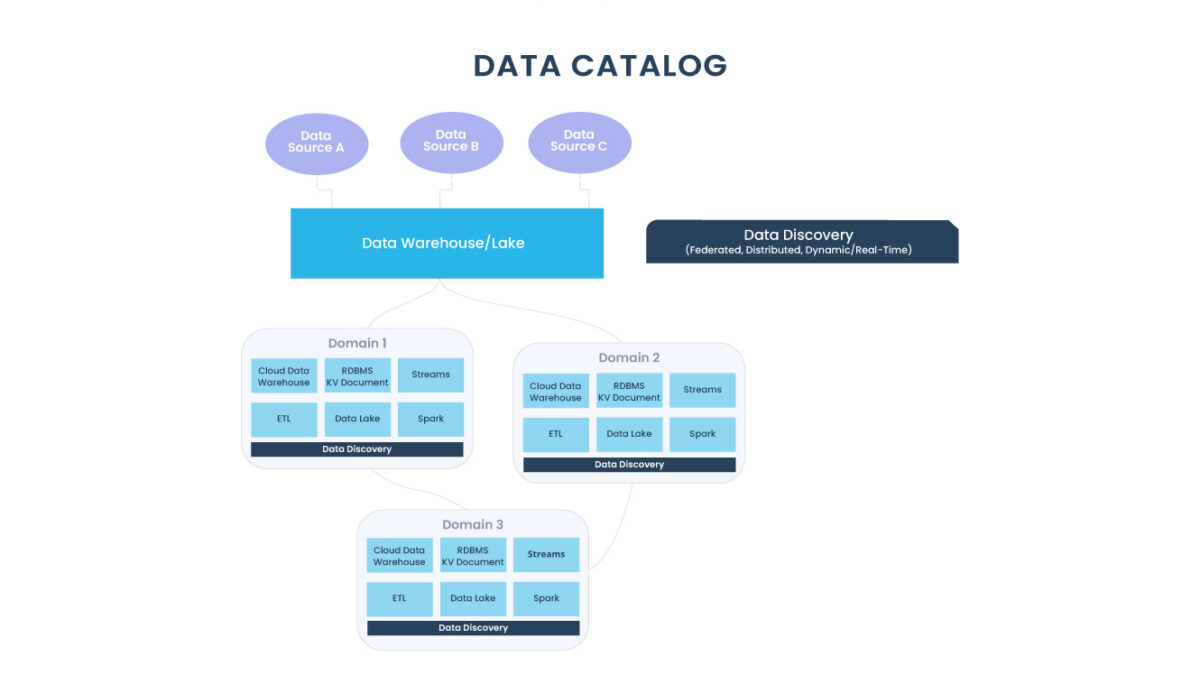
Data Catalog – Modern Data Stack
O mundo dos dados convergiu recentemente em torno do melhor conjunto de ferramentas para lidar com a complexidade de dados e velocidade do século 21, também conhecido como “MDS – Modern Data Stack”. Isso inclui configurar soluções como Snowflake, Databricks, Fivetran, Stitch, Atlan entre outras.
Por que a Modern Data Stack precisa mais do que nunca de um gerenciamento de metadados “moderno”?
Alguns anos atrás, os dados seriam consumidos principalmente pela equipe de TI de uma organização. No entanto, hoje as equipes de dados estão mais diversificadas do que nunca: engenheiros de dados, analistas, engenheiros de análise, cientistas de dados, gerentes de produto, analistas de negócios, cientistas de dados cidadãos e muito mais. Cada uma dessas pessoas tem suas próprias ferramentas de dados favoritas e igualmente diversas, desde SQL, Looker e Jupyter até Python, Tableau, dbt e R.
Essa diversidade é tanto uma força quanto um desafio. Todas essas pessoas têm maneiras diferentes de abordar um problema, ferramentas, conjuntos de habilidades, stack de tecnologia, maneiras de trabalhar… essencialmente, cada uma delas tem um “DNA de dados” único.
O resultado é muitas vezes o caos dentro da colaboração. Perguntas frustradas como “O que esse nome de coluna realmente significa?” e “Por que os números de vendas no painel estão errados novamente?”.
Essas perguntas não são novidade. Afinal, o Gartner publica seu Quadrante Mágico para Soluções de Gerenciamento de Metadados há mais de 5 anos.
Mas ainda não há uma boa solução. A maioria dos catálogos de dados são pouco mais do que soluções “remendos” da era Hadoop, em vez de acompanhar a inovação e os avanços por trás da stack de dados moderna atual.
Por que precisamos repensar nossa abordagem de gerenciamento de metadados e governança de dados?

Source Atlan
À medida que as empresas aproveitam cada vez mais os dados para impulsionar os produtos digitais, impulsionar a tomada de decisões e estimular a inovação, é fundamental entender a integridade e a confiabilidade desses ativos mais críticos. Por décadas, as organizações confiaram em catálogos de dados para fortalecer a governança de dados. Mas isso é suficiente?
Não é segredo: saber onde estão seus dados e quem tem acesso a eles é fundamental para entender seu impacto no negócio. Na verdade, quando se trata de construir uma plataforma de dados bem-sucedida, é essencial que seus dados sejam organizados e centralizados, além de serem facilmente detectáveis.
Análogo a um catálogo de biblioteca física, os catálogos de dados servem como um inventário de metadados e fornecem aos usuários as informações necessárias para avaliar a acessibilidade, a integridade e a localização dos dados. Em nossa era de inteligência de negócios de autoatendimento, os catálogos de dados também surgiram como uma ferramenta poderosa para gerenciamento de dados e governança de dados.
Não surpreendentemente, para a maioria dos líderes de dados, uma de suas primeiras prioridades é construir um catálogo de dados.
No mínimo, um catálogo de dados deve responder:
- Onde devo procurar meus dados?
- O que esses dados representam?
- Esses dados são relevantes e importantes?
- Como posso usar esses dados?
Ainda assim, à medida que as operações de dados amadurecem e os pipelines de dados se tornam cada vez mais complexos, os catálogos de dados tradicionais geralmente não atendem a esses requisitos.
Onde os catálogos de dados deixam a desejar?
Embora os catálogos tenham a capacidade de documentar dados, o desafio fundamental de permitir que os usuários “descubram” e obtenham insights significativos e em tempo real sobre a integridade de seus dados permanece em grande parte sem solução.
Os catálogos de dados como os que conhecemos não conseguem acompanhar essa nova realidade por três motivos principais:
1. Maior necessidade de automação
Os catálogos de dados tradicionais e as metodologias de governança geralmente dependem de equipes de dados para fazer o trabalho pesado da entrada manual de dados, responsabilizando-os pela atualização do catálogo à medida que os ativos evoluem. Essa abordagem não é apenas demorada, mas requer um trabalho manual significativo que, de outra forma, poderia ser automatizado, liberando tempo para engenheiros e analistas de dados se concentrarem em projetos que realmente criam impacto de analytics.
Como profissional de dados, entender o estado de seus dados é uma batalha constante e atende à necessidade de uma automação maior e mais personalizada. Talvez este cenário soe como um sino:
Antes das reuniões com as partes interessadas, você costuma entrar em ping freneticamente nos canais do Slack para descobrir quais conjuntos de dados alimentam um relatório ou modelo específico que você está usando e por que diabos os dados pararam de chegar na semana passada? Para lidar com isso, você e sua equipe se reúnem em uma sala e iniciam o whiteboard de todas as várias conexões upstream e downstream para um relatório chave específico?
Sua linhagem de dados parece uma tempestade de linhas e setas?
Muitas empresas que precisam resolver esse quebra-cabeça de dependência embarcam em um processo de vários anos para mapear manualmente todos os seus ativos de dados. Mesmo que você chegue ao objetivo final, isso representa um fardo pesado para a organização, custando tempo e dinheiro à sua equipe de engenharia que poderia ter sido gasto em outras coisas, como desenvolvimento de produtos ou realmente usar os dados.
2. Falta de Escalabilidade e Agilidade
Os catálogos funcionam bem quando os dados são estruturados, mas após 2020, nem sempre é esse o caso. À medida que os dados gerados por máquina aumentam e as empresas investem em iniciativas de ML, os dados não estruturados estão se tornando cada vez mais comuns, representando mais de 90% de todos os novos dados produzidos.
Normalmente armazenados em data lakes, os dados não estruturados não possuem um modelo predefinido e devem passar por várias transformações para serem utilizáveis e úteis. Os dados não estruturados são muito dinâmicos, com sua forma, origem e significado mudando o tempo todo à medida que passam por várias fases de processamento, incluindo transformação, modelagem e agregação. O que fazemos com esses dados não estruturados (ou seja, transformá-los, modelá-los, agregá-los e visualizá-los) torna muito mais difícil catalogá-los em seu “estado desejado”.
Além disso, em vez de simplesmente descrever os dados que os consumidores acessam e usam, há uma necessidade crescente de também entendê-los com base em sua intenção e propósito. Como um produtor de dados pode descrever um ativo seria muito diferente de como um consumidor entende sua função, e mesmo entre um consumidor para outro pode haver uma grande diferença em termos de compreensão do significado atribuído aos dados.
Por exemplo, um conjunto de dados extraído do Salesforce tem um significado completamente diferente para um engenheiro de dados do que para alguém da equipe de vendas. Embora o engenheiro entendesse o que “DW_7_V3” significa, a equipe de vendas estaria coçando a cabeça e tentando determinar se esse conjunto de dados se correlacionava com o painel “Previsões de Receita 2021” no Salesforce. E a lista continua.
As descrições de dados estáticos são limitadas por natureza. Em 2022, devemos aceitar e nos adaptar a essas dinâmicas novas e em evolução para realmente entender os dados.
3. Os dados são distribuídos; os catálogos não são
Apesar da distribuição da arquitetura de dados moderna (veja: Data Mesh) e o mov imento para adotar dados semiestruturados e não estruturados como norma, a maioria dos catálogos ainda trata os dados como uma entidade unidimensional. À medida que os dados são agregados e transformados, eles fluem por diferentes elementos da stack, tornando quase impossível documentá-los.
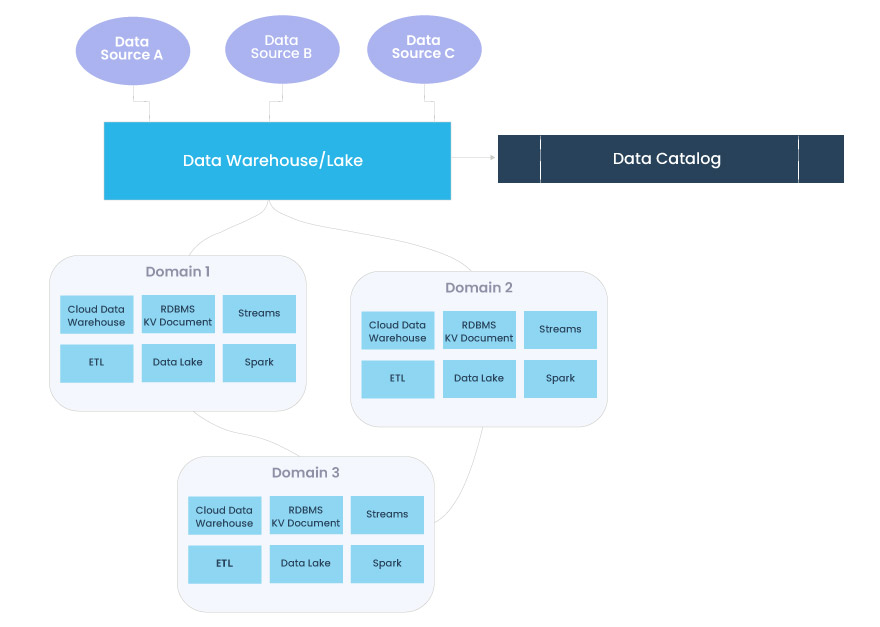
Os catálogos de dados tradicionais gerenciam metadados (dados sobre seus dados) no estado de ingestão, mas os dados mudam constantemente, dificultando a compreensão da sua integridade à medida que eles evoluem no pipeline.
Atualmente, os dados tendem a ser autodescritivos, contendo tanto os dados quanto os metadados, que descrevem seu formato e significado em um único pacote.
Como os catálogos de dados tradicionais não são distribuídos, é quase impossível usá-los como uma fonte central de verdade. Esse problema só aumentará à medida que os dados se tornarem mais acessíveis a uma variedade maior de usuários, de analistas de BI a equipes de operações, e os pipelines que alimentam ML, operações e análises se tornarem cada vez mais complexos.
Um catálogo de dados moderno precisa federar o significado dos dados nesses domínios. As equipes de dados precisam entender como esses domínios se relacionam e quais aspectos da visão agregada são importantes. Eles precisam de uma maneira centralizada de responder a essas perguntas distribuídas como um todo, em outras palavras, um catálogo de dados distribuído e federado.
Catálogo de Dados MDS (Modern Data Stack) = Discovery de Dados
Os catálogos de dados funcionam bem quando você tem modelos rígidos, mas à medida que os pipelines de dados se tornam cada vez mais complexos e os dados não estruturados se tornam o padrão de ouro, nossa compreensão (o que eles fazem, quem os usa, como são usados etc.) não reflete a realidade.
Acreditamos que os catálogos da próxima geração terão os recursos para aprender, entender e inferir os dados, permitindo que os usuários aproveitem seus insights de maneira self-service. Mas como a gente chega lá?
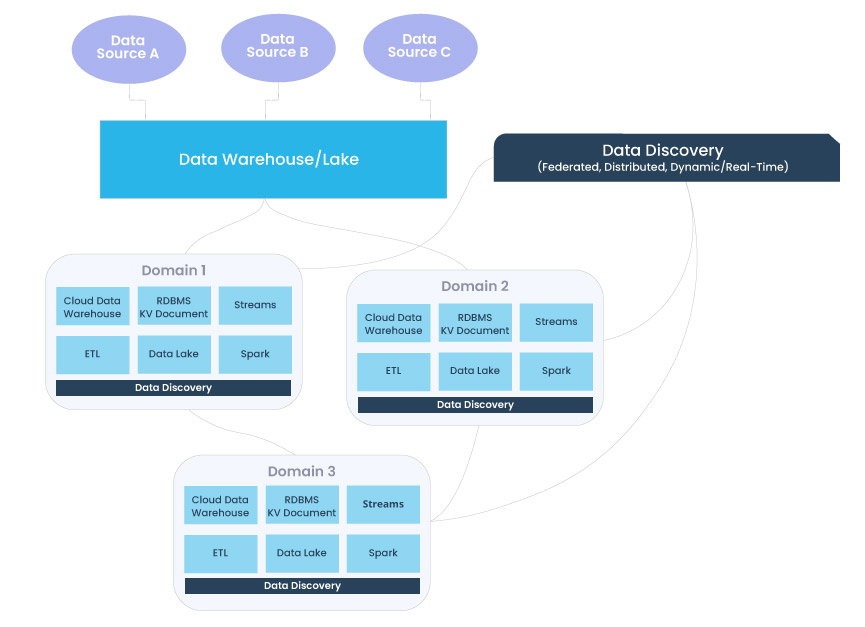
O Discovery de dados pode suprir o catálogo de dados moderno, fornecendo insights distribuídos em tempo real em diferentes domínios, ao mesmo tempo em que obedece a um conjunto central de padrões de governança.
Além de catalogar dados, metadados e estratégias de gerenciamento de dados, também devem incorporar a descoberta de dados, uma nova abordagem para entender a integridade de seus ativos distribuídos em tempo real. Tomando emprestado a arquitetura orientada a domínio distribuída proposta por Zhamak Deghani e o Data Mesh, o discovery de dados direciona que diferentes proprietários de dados são responsáveis por seus dados como produtos, bem como por facilitar a comunicação entre dados distribuídos em diferentes locais. Depois que os dados são servidos e transformados por um determinado domínio, os proprietários dos dados do domínio podem aproveitá-los para suas necessidades operacionais ou analíticas.
O Discovery de dados substitui a necessidade de um catálogo de dados fornecendo uma compreensão dinâmica e específica do domínio de seus dados com base em como eles estão sendo ingeridos, armazenados, agregados e usados por um conjunto de consumidores específicos. Assim como em um catálogo de dados, padrões de governança e ferramentas são federados nesses domínios (permitindo maior acessibilidade e interoperabilidade), mas, diferentemente de um catálogo, a descoberta apresenta uma compreensão em tempo real do estado atual dos dados em oposição ao seu ideal ou “catalogado”.
O discovery de dados pode responder a essas perguntas não apenas para o estado ideal dos dados, mas também para o estado atual em cada domínio:
- Qual conjunto de dados é mais recente? Quais conjuntos de dados podem ser preteridos?
- Quando foi a última vez que esta tabela foi atualizada?
- Qual é o significado de um determinado campo no meu domínio?
- Quem tem acesso a esses dados? Quando foi a última vez que esses dados foram usados? Por quem?
- Quais são as dependências upstream e downstream desses dados?
- Esses são dados de qualidade de produção?
- Quais dados são importantes para os requisitos de negócios do meu domínio?
- Quais são minhas suposições sobre esses dados e eles estão sendo atendidos?
Acreditamos que o catálogo de dados da próxima geração, ou seja, data discovery, terá as seguintes características:
Discovery e automação de autoatendimento
As equipes de dados devem poder aproveitar facilmente seu catálogo sem uma equipe de suporte dedicada. Autoatendimento, automação e orquestração de fluxo de trabalho para suas ferramentas de dados removem silos entre os estágios do pipeline de dados e no processo, facilitando a compreensão e o acesso aos dados. Uma maior acessibilidade naturalmente leva a uma maior adoção de dados, reduzindo a carga para sua equipe de engenharia.
Escalabilidade à medida que os dados evoluem
À medida que as empresas ingerem cada vez mais dados e dados não estruturados se tornam a norma, a capacidade de dimensionar para atender a essas demandas será fundamental para o sucesso de suas iniciativas. A descoberta de dados aproveita o aprendizado de máquina para obter uma visão geral de seus ativos à medida que são dimensionados, garantindo que sua compreensão se adapte à medida que seus dados evoluem. Dessa forma, os consumidores de dados são configurados para tomar decisões mais inteligentes e informadas, em vez de confiar em documentação desatualizada (também conhecida como dados sobre dados que se tornam obsoletos) ou pior tomada de decisão baseada em instinto.
Linhagem de dados para discovery distribuído
O discovery de dados depende muito da tabela automatizada e da linhagem em nível de campo para mapear as dependências upstream e downstream entre os ativos de dados. O Lineage ajuda a exibir as informações certas no momento certo (uma funcionalidade central da descoberta de dados) e estabelecer conexões entre os ativos para que você possa solucionar melhor quando os pipelines quebram, o que está se tornando um problema cada vez mais comum à medida que a modern data stack para acomodar ca sos de uso mais complexos.
Observabilidade de dados para garantir confiabilidade de dados em todos os momentos
A verdade é que de uma forma ou de outra sua equipe provavelmente já está investindo no discovery de dados. Seja através do trabalho manual que sua
equipe está fazendo para verificar os dados, regras de validação personalizadas que seus engenheiros estão escrevendo ou simplesmente o custo das decisões tomadas com base em dados quebrados ou erros silenciosos que passaram despercebidos. As equipes de dados modernas começaram a aproveitar abordagens automatizadas para garantir dados altamente confiáveis em todas as etapas do pipeline, desde o monitoramento da qualidade até plataformas de observabilidade de dados mais robustas e de ponta a ponta que monitoram e alertam sobre problemas em seus pipelines. Essas soluções notificam você quando os dados quebram para que você possa identificar a causa raiz rapidamente para uma resolução rápida e evitar tempo de inatividade futuro.
O discovery de dados capacita as equipes a confiar que suas suposições sobre os dados correspondem à realidade, permitindo a descoberta dinâmica e um alto grau de confiabilidade em sua infraestrutura de dados, independentemente do domínio.
Conclusão
Se dados ruins são piores do que nenhum dado, um catálogo de dados sem discovery de dados é pior do que não ter um catálogo. Para obter dados realmente detectáveis, é importante que eles não sejam apenas “catalogados”, mas também precisos, limpos e totalmente observáveis para ingestão e consumo, em outras palavras: confiáveis.
Uma abordagem forte para a discovery de dados depende do gerenciamento de dados automatizado e escalável, que funciona com a natureza recém-distribuída dos sistemas de dados. Portanto, para realmente permitir o discovery em uma organização, precisamos repensar como estamos abordando o catálogo de dados.
Somente entendendo seus dados, seu estado e como eles estão sendo usados em todos os estágios de seu ciclo de vida, entre domínios podemos começar a confiar neles.
Qualquer pessoa que trabalhe com dados sabe que já passou da hora dos catálogos acompanharem o restante da stack de dados moderna. Afinal, os dados não têm sentido sem os ativos que os tornam compreensíveis, documentação, consultas, histórico, glossários etc.
A triggo.ai é especialista em Data Analytics & AI, pioneira em XOps (DataOps|ModelOps|MLOps), e coloca a observabilidade bem como qualidade dos dados em primeiro plano, fale com um dos nossos especialistas!