Big Data já não é tão relevante como foi
O “velho” paradigma de big data dizia que você precisava coletar o máximo de dados possível (é o novo petróleo!) e construir uma arquitetura de escala correspondente. Todos esses dados seriam uma bala de prata, enquanto os cientistas de dados usariam a magia do machine learning para obter correlações anteriormente inconcebíveis e insights de negócios do que se pensava serem conjuntos de dados não relacionados.
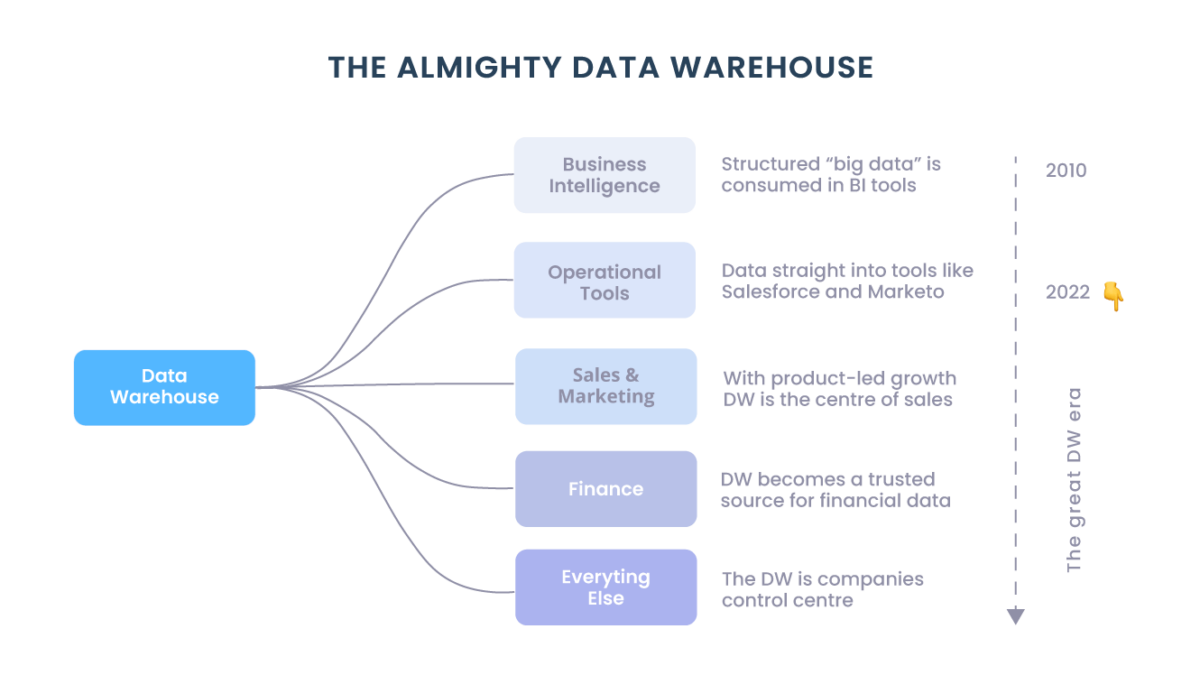
O volume reinou supremo na vanguarda da psique do engenheiro de dados porque, na era pré MDS (Modern Data Stack), apenas 4 anos atrás, a capacidade de armazenar e processar grandes volumes de dados era vista como o principal obstáculo arquitetônico ao valor comercial (hoje é diferente).
Volume e valor eram a mesma coisa. Afinal, quem sabia quais dados seriam valiosos para a caixa preta de machine learning?
Usando a abordagem moderna (Modern Data Stack) não conhecemos uma empresa que citou a falta de armazenamento ou computação como o principal obstáculo para alcançar seus resultados de D&A ou ML. Nem sobre as coisas incríveis que sua equipe faria “se ao menos pudessem coletar mais dados”.
De qualquer forma, inflar tabelas e terabytes pode revelar falta de organização, um potencial para aumento de incidentes de dados e um desafio para o desempenho geral. Em outras palavras, as equipes podem acumular volume de dados às custas de valor, veracidade e velocidade.
Para ser claro, existem algumas organizações que estão resolvendo problemas muito difíceis relacionados ao streaming de grandes quantidades de dados.
Mas esses são casos de uso especializados e, embora a demanda por dados de streaming apresente novos desafios de big data no horizonte, hoje a maioria das organizações desfruta de um momento tecnológico em que pode acessar armazenamento e computação suficientes para atender às necessidades da empresa sem grandes esforços.
Aqui estão algumas razões pelas quais você deve incentivar sua equipe a mudar a mentalidade de big data (volume) para torná-lo pequeno (menor):
- Os dados estão se tornando produtizados;
- O machine learning consome menos dados;
- A coleta é fácil, a documentação e a descoberta são difíceis;
- Você tem débitos técnicos de dados;
- Grande não é ruim, mas também não é necessariamente uma coisa boa.
Os dados estão se tornando produtizados
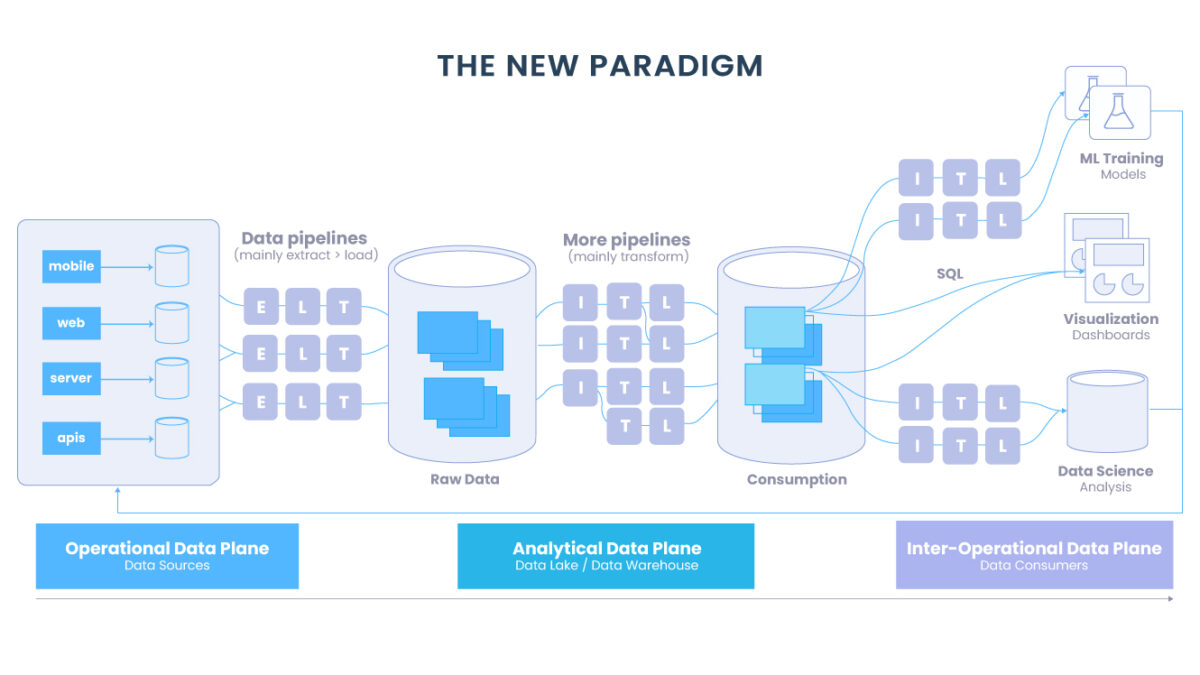
Com a emergente Modern Data Stack e conceitos como Data Mesh, o que descobrimos é que os dados não estão entregando valor quando estão desestruturados e desorganizados até que uma equipe de dados central prepare um pipeline complexo e ad-hoc ou insights para as partes interessadas do negócio.
Mais dados não se traduzem simplesmente em mais ou melhores decisões, na verdade podem ter o efeito oposto. Para serem orientados por dados, os domínios em toda a empresa precisam de acesso a dados significativos, em tempo quase real, que se encaixem perfeitamente em seus fluxos de trabalho.
Isso resultou em uma mudança no processo de entrega de dados que se parece muito com o processo de um produto. Os requisitos precisam ser reunidos; recursos iterados; autoatendimento habilitado, SLAs estabelecidos e suporte fornecido.
Quer o resultado final seja um relatório semanal, painel ou embedded em uma aplicação voltada para o cliente, os produtos de dados exigem um nível de polimento e curadoria que é contrário à expansão desorganizada.
Dessa forma, trabalhar antecipadamente para definir melhor as necessidades do consumidor e criar produtos de dados de autoatendimento úteis pode exigir menos (ou até mesmo uma quantidade cada vez menor) de dados.
As outras restrições são, obviamente, a qualidade e a confiança. Você pode ter o melhor data warehouse do mundo, mas os dados não terão consumidores se não forem confiáveis.
Tecnologias como Data Observability podem levar o monitoramento de dados em escala, de modo que não é necessário haver uma troca entre quantidade e qualidade, mas o ponto é que o volume de dados por si só é insuficiente para causar uma fração do impacto de uma boa manutenção e alta qualidade do produto de dados.
O machine learning consome menos dados
O machine learning nunca processaria toda a sua pilha de dados para encontrar a agulha do insight no palheiro das tabelas aleatórias. Acontece que, assim como os consumidores de dados, os modelos de machine learning também precisam de dados confiáveis de alta qualidade (talvez até mais).
Os cientistas de dados criam modelos específicos projetados para responder a perguntas difíceis, prever resultados de uma decisão ou automatizar um processo. Eles não apenas precisam encontrar os dados, eles precisam entender como eles foram derivados.
Ao mesmo tempo, as tecnologias e técnicas de machine learning estão melhorando e hoje precisam de menos dados de treinamento (embora ter mais dados de alta qualidade seja sempre melhor para precisão do que ter menos).
Até 2024, o Gartner prevê que o uso de dados sintéticos e o aprendizado de transferência reduzirão pela metade o volume de dados reais necessários para o machine learning.
A coleta é fácil, a documentação e a descoberta são difíceis
Muitas equipes seguem um caminho semelhante no desenvolvimento de suas operações de dados. Depois de reduzir o tempo de inatividade com a observabilidade, eles começam a se concentrar na adoção e democratização de dados.
No entanto, a democratização requer autoatendimento, que exige descoberta de dados robusta, que requer metadados e documentação.
Se formos honestos, parte do desafio é que ninguém, fora o raro administrador de dados, gosta de documentação. Mas isso não deve torná-lo menos prioritário para os líderes de dados (quanto mais automação aqui, melhor).
Você tem débitos técnicos de dados
Dívida técnica é quando uma solução fácil criará retrabalho em algum momento posterior. Muitas vezes cresce exponencialmente e pode esmagar a inovação, a menos que seja “paga em parcelas regulares”. Por exemplo, você pode ter vários serviços em execução em uma plataforma desatualizada e retrabalhar a plataforma significa retrabalhar os serviços dependentes.
Existem muitas concepções diferentes de débitos de dados, mas ressaltamos uma que combina o conceito de um “pântano de dados”, onde muitos dados mal organizados tornam difícil encontrar qualquer coisa, e tabelas com engenharia excessiva, onde longas consultas e séries SQL de transformações tornaram os dados frágeis e difíceis de contextualizar. Isso cria problemas sérios de usabilidade e qualidade.
Embora toda equipe tenha restrição de tempo, outro fator agravante é a falta de visibilidade da linhagem, muitas vezes tornando as equipes incapazes de descontinuar ativos de dados por medo de quebras não intencionais em algum lugar da stack.
Grande não é ruim, mas também não é necessariamente uma coisa boa
Tudo isso não quer dizer que não haja valor em “big” data. Isso seria uma correção excessiva. O que estamos dizendo é que está se tornando uma maneira cada vez mais pobre de medir a sofisticação de uma stack e uma equipe dados.
Em vez de perguntar “qual é o tamanho da sua stack ?”, faça perguntas com foco na qualidade ou uso em vez da coleta de dados:
Quantos produtos de dados você suporta? Quantos usuários mensais ativos eles suportam?
Qual é o seu tempo de inatividade de dados?
Quais modelos ou automações de machine learning críticos para o negócio sua equipe oferece suporte?
Como você está lidando com o ciclo de vida de seus ativos de dados?
Quer entender melhor o valor da sua plataforma de dados? Fale com um dos nossos especialistas, somos pioneiros e referência na abordagem Modern Data Stack.