Métricas para Observabilidade de Dados
Está muito claro para todos os profissionais que atuam com Data Analytics & Artificial Intelligence que a qualidade dos dados é essencial, o pilar mais importante para atingirmos o objetivo de gerar valor, seja no consumo ou na produtização de Analytics & AI.
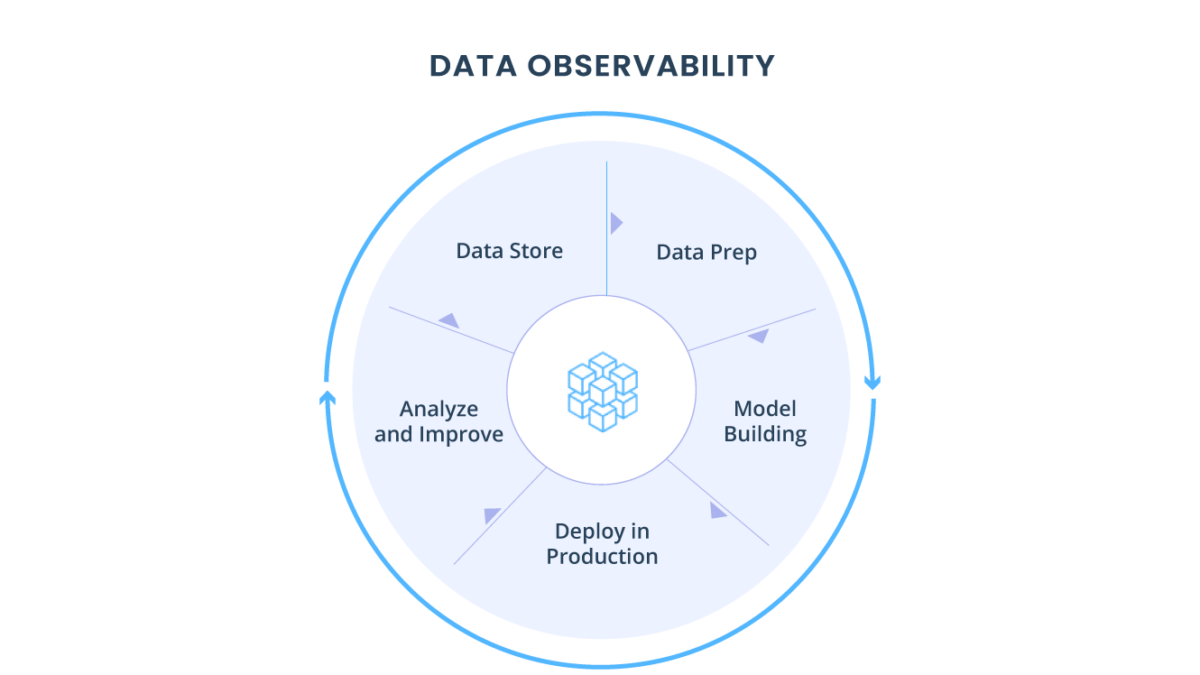
Abordamos recentemente em um artigo os 5 pilares sobre a observabilidade de dados. “Não importa quão fortes são nossos pipelines ou quantas vezes revisamos nosso SQL se nossos dados simplesmente não forem confiáveis.”
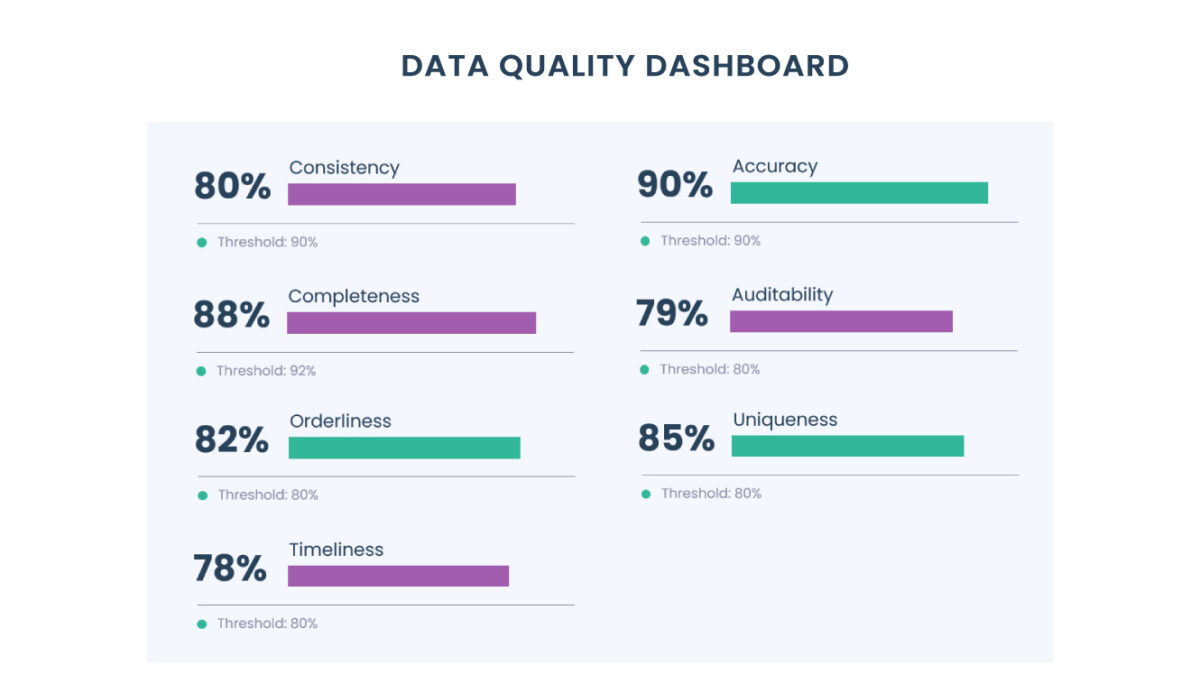
Em sua essência, os dados precisam de medição e podem ser resumidos em:
Por que medir a qualidade dos dados?
O que você não pode medir, você não pode melhorar, certo? Em partes sim, porém ser excessivamente obcecado com métricas provavelmente o levará ao erro. Então, é preciso focar no que realmente faz a diferença.
Existem muitas boas razões para medir as principais métricas de dados. Aqui estão algumas:
Porque alguns dados são muito importantes.
Se você é uma fintech, pode ser necessário enviar dados a reguladores ou usá-los para decidir quem deve ter permissão para se inscrever no seu produto. Se você é uma empresa de SaaS, pode ter alguns dados que decidem quais contas os usuários finais recebem no final do mês. Esses são os dados que você deseja acertar e, se não o fizer, pode ficar muito feio (um exemplo é o Facebook cobrando demais dos anunciantes devido à contagem excessiva).
Porque medir a qualidade dos dados ajuda a estabelecer padrões elevados para sua equipe.
Um painel do DataViz que não é atualizado antes das 9h quando a equipe de nível C analisa os KPIs ou se é informado com frequência sobre problemas de dados pelos consumidores antes de identificá-los, são exemplos que reduzem a confiança nos dados. Portanto, medir a qualidade pode ajudá-lo a ser proativo sobre onde melhorar os controles.
Porque assim você sabe onde fazer suas apostas.
Se você tem uma equipe de Analytics Engineer e quer que eles trabalhem em coisas mais importantes, ter uma compreensão clara da qualidade dos dados pode ajudá-lo a apontar para as áreas que estão indo bem e, também, destacar áreas em que precisam melhorar.
Quais métricas você deve usar?
Existem muitas ideias de métricas para reduzir o tempo de inatividade de dados ou minimizar erros detectados pelos usuários finais, mas essas não são suficientes por serem muito específicas. Você deve priorizar métricas mensuráveis para acompanhar e avaliar objetivamente sua equipe e resultados. Recomendamos agrupá-los em três categorias.
Qualidade: essas métricas ajudam você a entender a qualidade e a pontualidade de seus dados e quão bem você está preparado para detectar problemas quando algo dá errado.
Produtividade: o tempo gasto para melhorar a qualidade dos dados é uma faca de dois gumes e deve ser equilibrado com a realização de outros trabalhos estratégicos. Você deve acompanhar quanto tempo sua equipe está gastando no trabalho relacionado à qualidade dos dados.
Engajamento: muitas vezes, painéis e modelos de dados “são jogados por cima do muro” sem muita consideração por quem os usa. As métricas de engajamento ajudam a manter todos responsáveis de que o que está sendo criado também está sendo usado.
Algumas dessas métricas importantes:
% de dias que os modelos de dados são atualizados dentro do SLA: dá uma ideia clara de quando os dados estão prontos para uso. Se você sabe que seus executivos observam o painel de KPI todas as manhãs às 9h, responsabilize você e sua equipe por ter os dados prontos até então, definindo um SLA. Não há como esconder isso.
# falhas de teste de dados por semana: deixar os testes de dados falhando é semelhante à teoria das janelas quebradas. Ao colocar as falhas de teste na frente de sua equipe, é mais provável que eles as resolvam e não aceitem dezenas ou centenas de testes com falha sem solução.
Usuários ativos semanalmente de um painel: uma das melhores maneiras de fazer isso é ficar de olho em quem usa um produto de dados que, em muitos casos, é um painel. Isso não apenas lhe dá visibilidade se as pessoas usam seu trabalho, mas você também pode compartilhar o sucesso com membros da equipe, como engenheiros e analistas ou squads de produtos, para mostrar a eles que o trabalho upstream que eles colocam nos dados está valendo a pena.
O que é realmente empolgante é quando você começa a criar fluxos de trabalho em torno dessas métricas.
Quer melhorar a cobertura de teste de dados?
Estabeleça uma regra de que toda vez que alguém souber de um problema de dados que não foi detectado por um teste, ele deve adicionar um novo teste.
Quer fazer seus modelos de dados rodarem mais rápido?
Estabeleça uma regra que toda vez que alguém enviar código para o GitHub, você automaticamente verifica se isso afeta o tempo de execução do modelo de dados e gera um alerta se isso acontecer.
Você também pode agendar o envio semanal das métricas para torná-lo competitivo, responsabilizar as pessoas e comemorar o sucesso mostrando o quanto você melhorou.
Segmentar é fundamental!
Se você observar as métricas de dados em diferentes segmentos, isso se tornará muito mais interessante e acionável. Os seguintes segmentos são particularmente interessantes:

Equipe/Squad: se você faz parte de uma equipe de dados maior, é importante dividir a qualidade dos dados por equipe para entender como cada uma está se saindo. Da mesma forma, se você tiver uma configuração descentralizada com muitos squads de produtos, tente fazer com que os produtores de dados assumam a propriedade conjunta da qualidade dos dados, compartilhando as principais métricas com eles.
Criticidade: nem todos os dados devem ser tratados da mesma forma. Um erro em um modelo de dados usado apenas por você e alguns colegas próximos pode ter um impacto muito diferente de um erro no painel de KPI de nível superior ou em um serviço que alimenta um sistema de ML de nível de produção. A maioria das equipes tem uma maneira de saber sobre isso, por exemplo, marcando modelos de dados como “camada 1”, “crítico” ou “padrão ouro”.
Tempo: você quer ser capaz de entender se está melhorando ou deteriorando a qualidade dos dados ao longo do tempo e como isso se parece com as equipes e squads.
Usuários finais: da mesma forma que você segmenta modelos de dados por criticidade, você pode segmentar usuários finais. Por exemplo, você pode ter um filtro para ver quais painéis eles usam e se estão usando dados errados. Embora todos devam esperar uma ótima qualidade de dados, geralmente é mais importante prestar atenção extra aos dados que são usados por muitos funcionários seniores.
Como começar?
Comece com algumas métricas e fique com elas. Otimize para dados acessíveis e evite criar muito trabalho manual, por exemplo, fazendo com que as pessoas insiram o tempo gasto na resolução de problemas de dados em uma determinada semana. Isso será muito subjetivo e sua equipe ficará cansada disso.
Seja consistente e tenha um cronograma regular de análise das métricas. Talvez você as revise em sua reunião quinzenal da equipe de dados ou as disponibilize semanalmente. Seja qual for o seu caminho, coloque-as na frente das pessoas regularmente para que não seja apenas mais um processo brilhante que não é usado.
A triggo.ai é especialista em Data Analytics & AI, pioneira em XOps (DataOps|ModelOps|MLOps), e coloca a observabilidade bem como qualidade dos dados em primeiro plano, fale com um dos nossos especialistas!