Medindo e Mantendo Alta Confiabilidade de Dados
O mundo dos dados está décadas atrás do mundo da fabricação automotiva, que aprendeu há muito tempo a não deixar dados ruins entrarem em um sistema.
Uma filosofia fundamental que a Toyota introduziu para parar uma linha de fabricação, quando uma anormalidade é detectada, ficou conhecida como “Jidoka”. O conceito apresenta um paradigma simples, mas poderoso, com o qual devemos aprender na engenharia de dados.
Jidoka → Por definição, Jidoka é um método Lean que é amplamente adotado na fabricação e desenvolvimento de produtos. Também conhecido como autonomação, é uma maneira simples de proteger a sua empresa contra a entrega de produtos de baixa qualidade ou com defeitos ao seu consumidor.
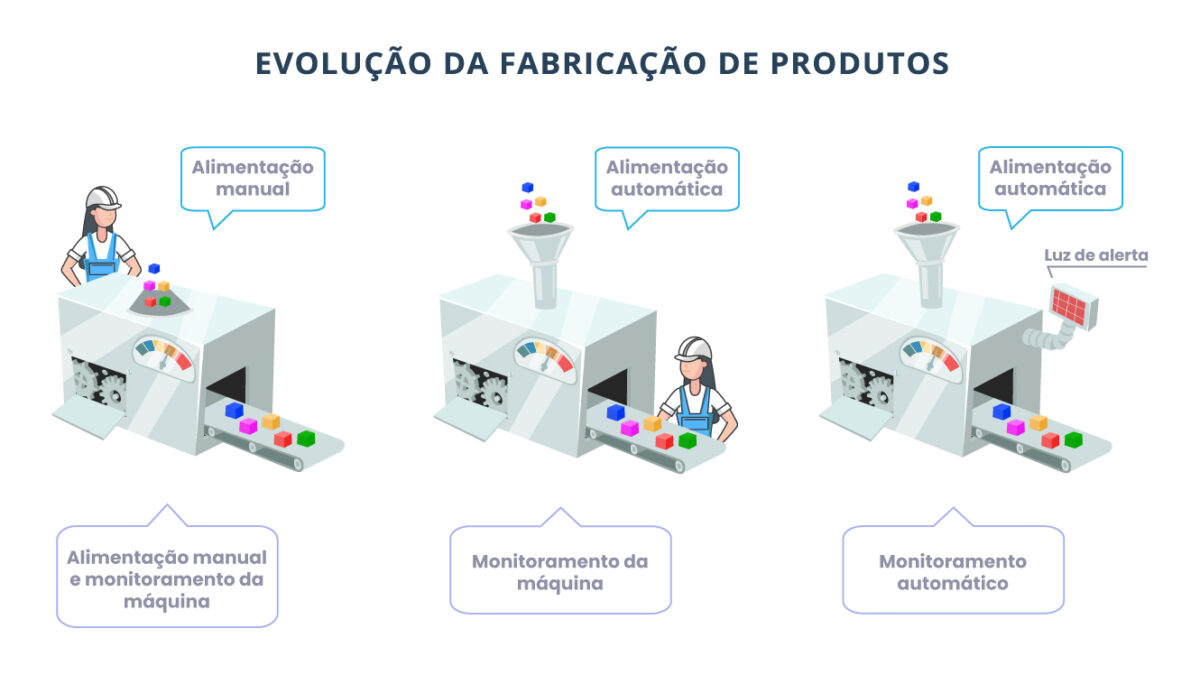
A imagem abaixo representa de maneira simples e visual sobre as 3 fases de melhorias na evolução da fabricação de produtos na indústria, abordado pela Toyota.
Se os pipelines pudessem parar quando os dados ruins fossem introduzidos, seria possível impedi-los de fazer o seu caminho para a produção.
- Trabalhe com os produtores de dados para corrigir dados na fonte (corrigir seu contrato de dados).
- Aborde o problema no pipeline, antes que os dados ruins cheguem aos sistemas de produção.
Esse é um conceito simples, mas que tem implicações de longo alcance em torno da qualidade dos dados na produção.
Airbnb escreveu, em uma postagem de 2020 em seu blog de engenharia, “a liderança estabelece altas expectativas de pontualidade e qualidade dos dados” quanto à necessidade de fazer investimentos em sua qualidade de dados e exercício financeiro. Enquanto isso, Krishna Puttaswamy e Suresh Srinivas, ex-engenheiros no Uber, escreveram em um artigo do blog de engenharia da Uber, de 2021, que big data de alta qualidade está no core desta enorme plataforma de transformação.
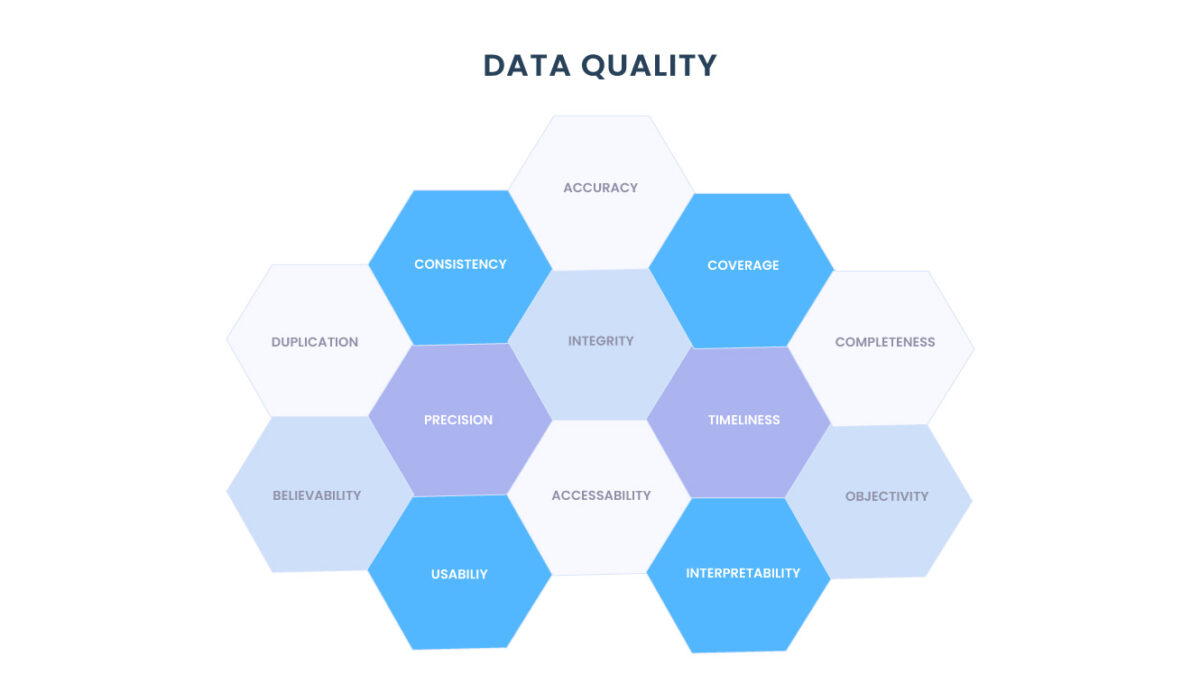
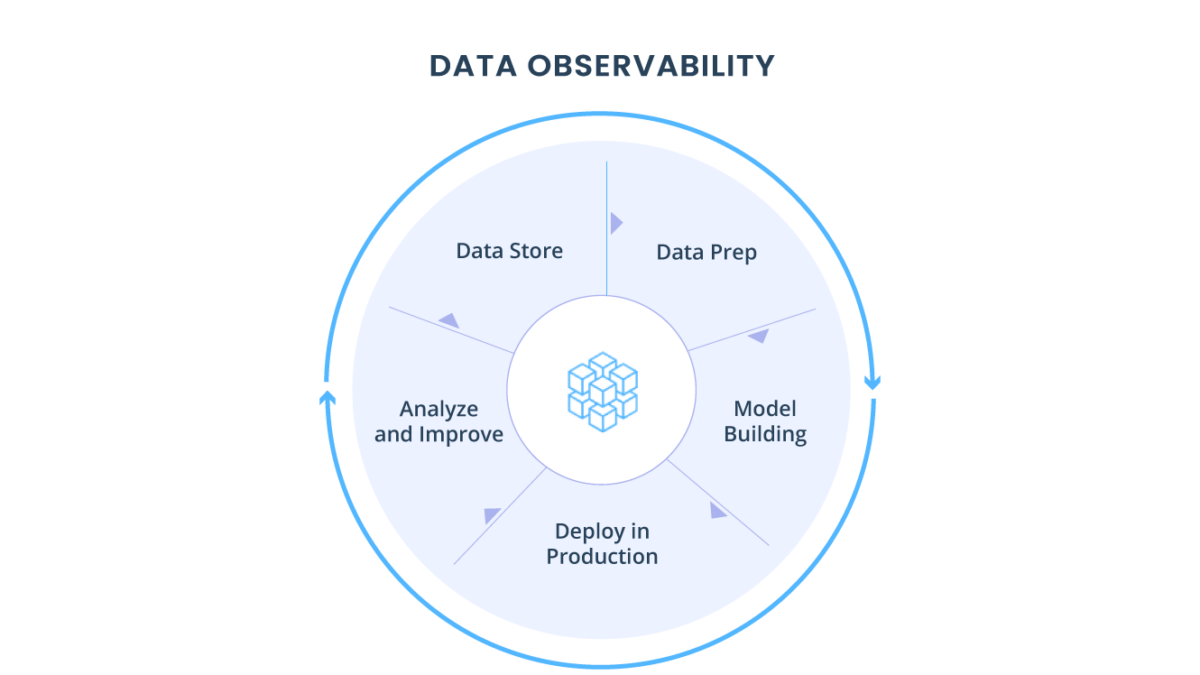
Não é segredo: a qualidade dos dados é a prioridade de algumas das melhores equipes de dados (leia nosso artigo sobre Observabilidade de Dados).
Ainda assim, há muitas coisas para escrevermos sobre esse assunto: como isso é realmente na prática?
Data Reability → a capacidade de uma organização de fornecer alta disponibilidade e integridade de dados durante todo seu ciclo de vida é o resultado da alta qualidade dos dados.
Empresas ingerem mais dados operacionais e de terceiros do que nunca, com funcionários de toda a organização interagindo com esses dados em todos os estágios de seu ciclo de vida, portanto a qualidade torna-se cada vez mais importante.
A confiabilidade dos dados deve ser intencionalmente construída em todos os níveis de uma organização, desde os processos e tecnologias que você utiliza para construir e gerenciar sua data stack até a maneira como você se comunica e faz a triagem de problemas de dados mais adiante.
Agora que entendemos melhor o estado da qualidade dos dados, vamos ver o que tudo isso significa na prática, começando pela ingestão. No entanto, seríamos negligentes não discutir algumas das melhores práticas fundamentais que garantem alta qualidade de dados antes da ingestão para o data warehouse ou lakehouse.
É comum empresas ingerirem dados de terceiros, internos e externos, dependendo das necessidades do negócio. Sua tomada de decisão é apenas tão boa quanto os dados que você está usando para insights e análises: garbage in, garbage out. Portanto, é importante certificar que a organização tenha o conjunto certo de práticas para garantir a qualidade dos dados.
Para conseguir isso, organizações começaram a estabelecer um rigoroso controle de qualidade para todos os dados que entram em seu ecossistema de dados. Embora os problemas de qualidade possam ocorrer em qualquer ponto do pipeline, a maioria das equipes concordará que capturar e corrigir esses problemas no ponto de ingestão ajudará a minimizar as chances de dados de baixa qualidade.
As melhores práticas, como limpeza, organização (processo de estruturação, enriquecendo os dados em um formato desejado) e o teste de dados, são maneiras pelas quais as empresas garantem que a qualidade dos dados esteja de acordo com as suas necessidades. E com a tecnologia avançando ao longo dos anos na indústria de dados, uma abundância de ferramentas surgiu para automatizar essas tarefas.
Essas ferramentas permitem examinar automaticamente aspectos dos dados, como formato, consistência, completude, frescor e singularidade. Ao automatizar este processo, as organizações não apenas economizam tempo e recursos na limpeza de dados, mas garantem que a qualidade dos dados recebidos seja constantemente controlada e gerenciada sempre que os dados entram em seu ecossistema.
A limpeza de dados (também comumente chamada de limpeza) envolve preparar e modificar dados para análise futura, removendo dados incompletos, irrelevantes, incorretos ou duplicados de um conjunto. Enquanto o processo de limpeza pode ser tedioso, é uma responsabilidade muito importante para uma equipe de dados. Na verdade, tal processo na maioria das organizações é de propriedade da engenharia de dados e/ou equipe de ciências, no entanto, é importante educar o resto da organização sobre a importância da limpeza, pois todos desempenham um papel fundamental para garantir a integridade dos dados.
Ao lidar com dados ausentes ou imprecisos, muitas empresas recorrem a um processo chamado de enriquecimento de dados, onde as organizações são capazes de mesclar e adicionar dados próprios ou de terceiros aos conjuntos de dados com os quais já estão trabalhando. Assim, as organizações são capazes de agregar mais valor aos seus conjuntos de dados, tornando-os mais úteis e confiáveis.
Após a etapa de limpeza, o teste de dados é sua melhor linha de defesa contra a baixa qualidade antes ingestão.
O teste é o processo de validação das suposições sobre os dados, realizado antes ou durante a produção. Escrevendo testes básicos que verificam cenários como uniqueness e not_null, são maneiras pelas quais as organizações podem testar as suposições que elas fazem sobre seus dados de origem. Também é comum utilizar os testes para garantir que os dados estejam no formato correto para a equipe trabalhar e que atendam às necessidades do negócio.
Testes Básicos:
Teste unitário → Os testes de unidade verificam se uma linha de código (SQL) faz o que deveria fazer; eles podem ser usados com granularidade de dados muito pequenas. Ao testar dados de unidade, você deve separar a lógica de negócio do “glue code”.
Teste funcional → Testes funcionais são usados com grandes conjuntos de dados, e, muitas vezes, são separados em validação de dados, integridade, ingestão, processamento, armazenamento e ETL. Esse tipo de teste ocorre frequentemente no pipeline (camada pré-analítica).
Teste de integração → Os testes de integração são usados para garantir que seu pipeline de dados atenda aos seus critérios de validade (ou seja, dentro dos intervalos esperados); geralmente, as equipes executam dados falsos por meio do pipeline usando esses testes antes de aproveitar os dados de produção.
Algumas verificações comuns de qualidade de dados incluem:
Valores nulos → Algum valor é desconhecido (NULL)?
Freshness → Quão atualizados estão meus dados? Foi atualizado há uma hora ou dois meses atrás?
Volume → Quantos dados são representados por esse conjunto de dados? 200 linhas se transformaram em 2.000?
Distribuição → Meus dados estão dentro de um intervalo aceito? Minhas unidades são as mesmas dentro de uma determinada coluna?
Valores ausentes → Está faltando algum valor no meu conjunto de dados?
Como você escreveria isso?
Em um artigo posterior, passaremos por uma lista de dados comuns e testes em SQL que podem ser aplicados a muitas linguagens de código aberto (com sintaxe variável, é claro), mas, para fins de explicação, vamos ver um exemplo de conjunto de dados.
Vamos supor que você seja uma empresa de marketing digital que trabalha com um conjunto de dados que rastreia sua base de clientes, incluindo localização (CIDADE) e quanto eles estão pagando por uma assinatura (PREÇO) dos seus serviços. Existem 500 registros neste conjunto de dados e 5 colunas.
Colunas: CIDADE, PAÍS, PREÇO, NOME DO CLIENTE, PRODUTO.
Se você quiser testar os dados para garantir que está executando apenas um pipeline em clientes que vivem em SÃO PAULO, você pode executar um comando SQL que diz:
SELECT * FROM Clientes WHERE Cidade = “São Paulo”
E se você quiser entender se existem valores nulos em CIDADE, você pode consultar:
SELECT * FROM Clientes WHERE Cidade IS NULL
Se você quiser entender se algum produto é mais caro que $ 4,50 ou menos caro do que $ 8,50, você pode executar:
SELECT * FROM Produto WHERE Preço > 4.50 AND Preço < 8.50
E isso apenas “faz cócegas” na superfície dos tipos de testes que você pode executar para manter a qualidade de seus dados.
Como resultado, os membros da equipe geralmente dividem as responsabilidades de teste sobre os conjuntos de dados, com analistas e engenheiros responsáveis por criar e manter testes para os conjuntos nos quais estão construindo pipelines e interagindo diariamente. Algumas empresas contratam equipes inteiras de garantia de qualidade de dados para lidar com os testes, com possibilidades de incluir a criação de testes para casos de uso de negócios e a manutenção de testes existentes.
Nos últimos anos, ferramentas, incluindo soluções de código aberto como Apache Griffin e Great Expectations, surgiram na categoria de teste de dados para ajudar os engenheiros e analistas automatizarem o processo de teste em diferentes estágios do pipeline.
DBT (data build tool), por exemplo, é uma solução muito indicada no pipeline de dados que possui capacidade de testes unitários. Essas ferramentas também ajudam as equipes de dados a documentar informações importantes sobre conjuntos de dados (em outras palavras, metadados).
Não podemos deixar de enfatizar a importância de testar seus dados de maneira suficiente antes da produção:
Mas, para testar bem seus dados, você precisa de uma compreensão clara da integridade deles antes de executar seus pipelines. Falaremos sobre como garantir a integridade e a observabilidade dos dados em outro artigo.
Tenha em mente que o teste de dados apenas detecta problemas de qualidade esperados e não têm escalabilidade ou conhecimento para explicar problemas de qualidade “desconhecidos”. Dados mudam muito, mesmo durante a produção, por isso, é importante complementar os testes com monitoramento reativo e detecção de anomalias.
A triggo.ai é especialista em Data Analytics & AI, pioneira em XOps (DataOps|ModelOps|MLOps), e coloca a observabilidade bem como qualidade dos dados em primeiro plano, fale com um dos nossos especialistas!