Como medir a qualidade de dados
Fundamental para começar: você deve identificar os 20% de seus dados que geram 80% do valor em suas decisões e processos de negócios para, então, priorizar seus esforços de melhoria e medição de qualidade no subconjunto de dados de alto valor antes de aplicar essas técnicas de forma mais ampla.
Você precisa de informações confiáveis para tomar decisões sobre riscos e resultados de negócios. Muitas vezes, essas informações são tão valiosas que você pode tentar comprá-las diretamente por meio de provedores de dados terceirizados para aumentar seus dados internos. No entanto, com que frequência você considera o impacto da qualidade dos dados em suas decisões? Informações ruins podem ter efeitos prejudiciais nas decisões de negócios e, consequentemente, no desempenho, inovação e competitividade da sua empresa.
As organizações que tratam a informação como um ativo corporativo devem se engajar na mesma disciplina de avaliação de qualidade com seus ativos tradicionais. Isso significa monitorar e melhorar continuamente a qualidade e o valor de suas informações.
Avaliar a qualidade dos dados é um componente pequeno, mas é muito importante para medir o valor geral dos ativos de informação.
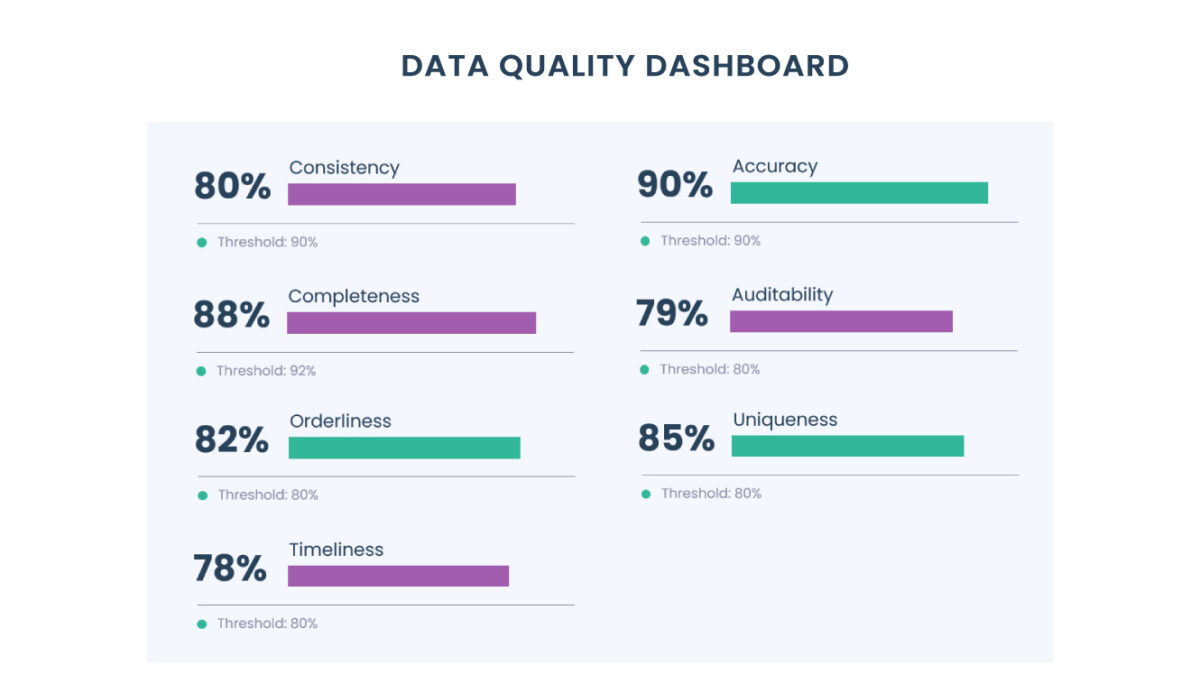
Métricas de qualidade de dados objetivas
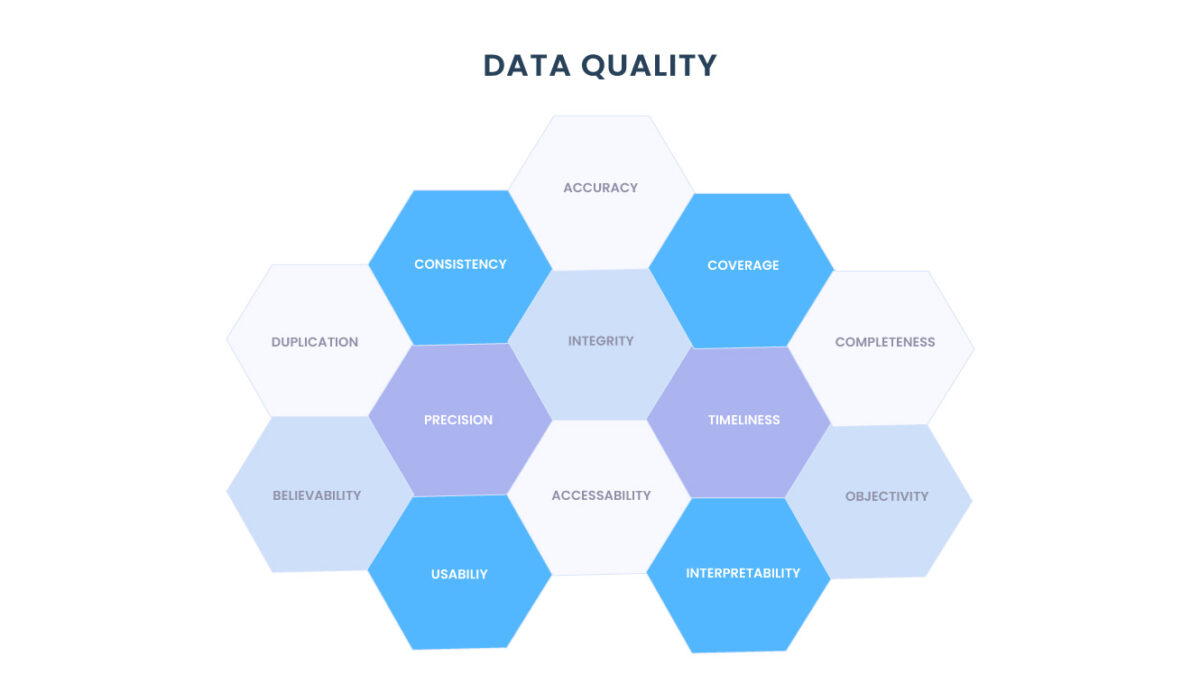
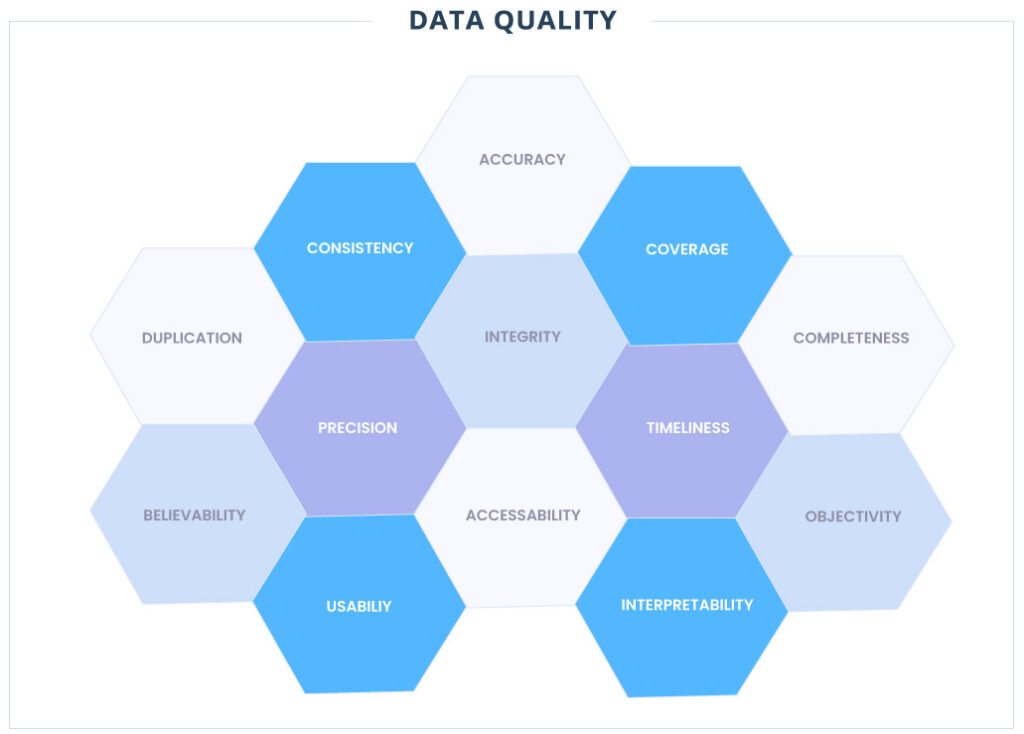
As métricas de qualidade de dados mais comuns podem ser divididas nas seguintes categorias:
- Validade: com que precisão cada campo de dados disponível representa a realidade?
- Cobertura: qual percentual dos eventos ou objetos de interesse possuem registros? Por exemplo, se você se preocupa com todas as empresas da América do Norte, qual é a porcentagem de empresas norte-americanas representadas no conjunto de dados?
- Completude: de todos os registros fornecidos, qual porcentagem dos campos disponíveis tem um valor?
- Integridade: se houver relacionamentos presentes nos dados, com que frequência as expectativas entre os atributos relacionados são violadas? Por exemplo, o total de recursos arrecadados por uma empresa deve sempre ser igual à soma dos eventos individuais de captação de recursos dessa empresa ou as chaves estrangeiras devem sempre apontar para registros existentes (integridade referencial).
- Consistência: quão consistentes são os dados em formato e estrutura dentro e entre conjuntos de dados?
- Duplicação: qual porcentagem de todos os registros são duplicados?
- Precisão: quão exatos são os dados? Qual é o nível de detalhe de dados não estruturados, como texto ou imagens? Qual é a frequência de entrega dos dados fornecidos?
- Tempestividade: qual é a probabilidade de que os dados representem os valores no mundo real em um determinado momento? Observe que não estamos interessados no intervalo de tempo entre um evento que acontece no mundo real e o evento que aparece no conjunto de dados. Na prática, isso é extremamente difícil de verificar e a empresa geralmente se preocupa mais com a sincronização do conjunto de dados com a fonte do que com o atraso de tempo em si.
- Acessibilidade: o número de processos de negócios ou pessoal que pode acessar e se beneficiar dos dados.
Métricas subjetivas de qualidade de dados
Nem todos os aspectos da qualidade dos dados podem ser considerados isoladamente de seu relacionamento com os usuários. Algumas métricas de qualidade são puramente subjetivas, mas têm um impacto significativo na utilização dos ativos de dados. Essas métricas geralmente são medidas por meio de pesquisas com usuários.
- Credibilidade: os usuários confiam nos dados que estão visualizando ou estão sendo burlados ou substituídos por fontes alternativas de informações semelhantes?
- Usabilidade: com que facilidade o valor pode ser extraído dos dados para realizar alguma função de negócios?
- Objetividade: quão imparcial é a fonte dos dados aos olhos dos usuários?
- Interpretabilidade: quão compreensíveis são os dados? Existe documentação suficiente para apoiar os dados brutos?
Observe que as pessoas podem usar a palavra “qualidade” para representar o valor dos dados, mas esse é um tópico profundo a ser abordado separadamente em um próximo artigo.
Medindo a qualidade dos dados na prática
As medidas de qualidade de dados têm uma variedade de usos e, um desses, é a gestão da qualidade da informação produzida.
O ato de medir por si só já pode levar a um aumento na qualidade dos dados, afetando uma mudança na forma como as pessoas gerenciam e trabalham com os dados. Você também pode usar essas práticas para comparar provedores de dados de terceiros que afirmam ter a melhor qualidade de dados entre todos os concorrentes.
Na prática, você provavelmente verá o maior aumento desse exercício de medição ao aplicá-lo onde houver mais fluxo de dados. Isso tende a ser entre sistemas de software e pipelines de dados analíticos. Na verdade, se você já tiver instrumentado bem seus negócios, a maioria dos dados de provedores e processos de negócios de terceiros deve fluir para um armazenamento onde o monitoramento de qualidade pode ser centralizado.
Implementando o monitoramento de qualidade de dados
Embora a execução de uma pesquisa para medir a qualidade subjetiva dos dados seja relativamente simples, as métricas objetivas podem ser um desafio para implementar. Das 9 métricas de qualidade de dados objetivas, apenas as métricas de Completude, Integridade, Precisão e Acessibilidade podem potencialmente ser completamente automatizadas.
Você pode monitorar essas métricas aplicando testes de dados escritos em SQL, outra linguagem de programação ou software para fins especiais. Uma maneira de monitorar a qualidade dos dados usando SQL é criar painéis de BI que rastreiam “visualizações de qualidade de dados”, que executam consultas de dados incorretos, retornando quaisquer linhas que desafiem as expectativas.
Como alternativa, esses testes de dados podem ser incluídos como parte ou pré-requisito para seus pipelines de transformação usando ferramentas como dbt-expectations para dbt ou a biblioteca Great Expectations Docs em fluxos de trabalho de orquestração genéricos.
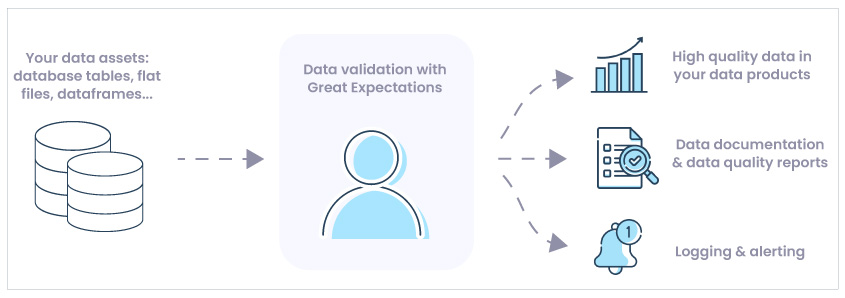
Para as outras métricas, você pode começar com um humano no circuito para fornecer a verdade e usar amostragem aleatória para se beneficiar da eficiência proporcionada pelos testes estatísticos. Em alguns casos, você pode aproveitar a automação não apenas para medir, mas também para corrigir alguns desses problemas de dados.
Abaixo, descrevemos exemplos de estratégias que você pode usar para avaliar a métrica de qualidade de dados campo a campo. Para desenvolver uma “pontuação de integridade” geral para um conjunto de dados específico, você pode aplicar agregação adicional, se necessário.
Validade
Field Accuracy = [# records with accurate field info] / [# of records with a value in the field]
Para obter a precisão de cada campo, você precisa de alguns “registros de ouro” que considera serem a verdade absoluta. Você pode obter essa verdade básica anotando manualmente um conjunto de entidades ou usando uma fonte de dados alternativa de alta precisão como proxy.
Cobertura
Field Coverage = [# real-world entities in the dataset] / [# real-world entities]
Você pode obter uma medição automatizada de cobertura se seu “universo” de entidades for predefinido ou facilmente estimado. Se não for esse o caso, você pode usar o número de eventos “perdidos” como proxy para cobertura. Isso pode ser capturado em seus processos de negócios à medida que você percebe que algumas entidades foram perdidas.
Field Miss Rate = [# missed real-world entities touching system] / [# real-world entities touching system]
Duplicação
Taxa de duplicação = [# duplicatas detectadas] / [# total de registros no conjunto de dados]
Essa métrica aparentemente simples é extremamente difícil de medir porque registros duplicados são difíceis de detectar. Você pode usar anotadores humanos e estratégias de amostragem inteligentes para aproximar a taxa geral de duplicatas do seu conjunto de dados, mas isso é difícil de dimensionar.
Dado que seu objetivo final é eliminar duplicatas, é melhor usar um fornecedor de software externo. Isso é principalmente um problema resolvido para pessoas físicas e jurídicas, e estratégias genéricas de eliminação de duplicação estão disponíveis para problemas de duplicação menos comuns.
No caso raro de fornecedores de correspondência de registros não atenderem às suas necessidades, você terá que preparar um processo de desduplicação de registros do zero (diga se esse é um tópico que você gostaria de ler em um próximo artigo).
Enfim, a melhor coisa que você pode fazer é implementar a validação apropriada para evitar que duplicatas entrem em seu sistema, porque tende a ser muito mais fácil evitar problemas de entrada de dados do que os corrigir.
Pontualidade
Pontualidade = [# registros no conjunto de dados que representam com precisão o valor atual do mundo real] / [# registros totais]
Como explicamos anteriormente, é difícil de medir a diferença no tempo do relógio entre um evento do mundo real e sua aparência no conjunto de dados. Além disso, não é tão importante quanto a probabilidade de que os valores estejam sincronizados quando os dados são observados.
Para medir a pontualidade, você pode pegar uma pequena amostra de “registros dourados” para os quais você tem o valor atual (ou acabou de anotar) e calcular a razão entre os valores correspondentes e o número total de registros.
Acessibilidade
A métrica de acessibilidade é altamente dependente do contexto. Você pode achar suficiente medir o número de usuários que acessam os dados durante algum período. Alternativamente, você pode estar interessado no número de sistemas em que os dados estão disponíveis e compará-lo com o número de sistemas em que os dados são relevantes ou aplicáveis.
Nas métricas acima, não era incomum sugerir que introduzíssemos um “humano no loop” para fornecer uma anotação confiável dos valores de destino. Para implementar isso na prática, você pode usar plataformas low-code e no-code, como retool ou bubble, para acelerar um processo de anotação em questão de horas.
As métricas derivadas de um processo de amostragem fornecem apenas a média da distribuição de valores potenciais que poderiam ter produzido esse resultado. Você pode estar interessado em quantificar a incerteza introduzida pelo processo de amostragem e, para conseguir isso, é possível calcular um intervalo de confiança de 90% para os valores observados, parametrizando uma distribuição Beta da seguinte forma:
Métrica ~ Beta (⍺ = Numerador + 1 , β = Denominador – Numerador + 1)
Uma maneira fácil de pensar sobre isso em termos de “acertos” e “erros”:
Métrica ~ Beta (⍺ = Acertos + 1 , β = Acertos + 1)
Para obter os limites do intervalo de confiança de 90% para a métrica usando Excel ou Planilhas Google, você pode usar a função BETA.INV(probability, ⍺, β).
Por exemplo, se você detectou 1 duplicata de uma amostra aleatória de 50, você calcularia os limites da seguinte forma:
Duplication Rate = [# duplicates detected] / [# total records in the dataset]
5% Lower Bound => BETA.INV(0.05, 1+1, 49+1) = 0.7%
95% Upper Bound => BETA.INV(0.95, 1+1, 49+1) = 8.9%
Isso significa que há uma chance de 90% de termos os resultados que obtivemos com uma taxa geral de duplicação de 0,7% a 8,9%!
Conhecer a incerteza associada às suas métricas certamente é útil para determinar se a qualidade de seus dados está realmente mudando ou se é apenas um artefato de flutuações associadas a um processo aleatório.
Conclusão
Exploramos as dimensões centrais da qualidade dos dados e como medi-las para reduzirmos o desperdício gerado pelos caminhos seguidos como resultado de informações não confiáveis.
O objetivo de acompanhar essas métricas de qualidade de dados não é obter uma medição perfeita, mas sim identificar se estamos indo na direção certa e, acima de tudo, agir sobre essas informações para melhorar nossos processos.
Antes de tentar medir a qualidade dos dados em todos os sistemas da sua empresa, gostaria de lembrá-lo de que nem todos os dados têm o mesmo valor e a medição não é gratuita. Você deve identificar os 20% de seus dados que geram 80% do valor em suas decisões e processos de negócios para priorizar seus esforços.
Mas, como exatamente você pode avaliar e medir o valor dos dados e como podemos usar esse conhecimento para informar nossa estratégia de dados?
A triggo.ai é especialista em Data Analytics & AI e, pioneira em XOps (DataOps|ModelOps|MLOps), coloca a observabilidade bem como qualidade dos dados em primeiro plano, fale com um de nossos especialistas!